웹크롤링 - 외부 파일 읽어오기
🐤 행렬데이터 처리 라이브러리
import pandas as pd
🐤 외부 파일 읽어들이기
file_path = "./data/movie_reviews.txt"
# 구분자 사용해서 txt저장했을 시 구분자를 명시해줘야함
df_org = pd.read_csv(file_path,
# 구분자 알려주기
delimiter = "\t",
# 제목 지정해주기
names = ["title", "score", "label", "comment"])
df_org

웹크롤링 - 데이터 전처리
🐤 결측치 확인
df_org.info()

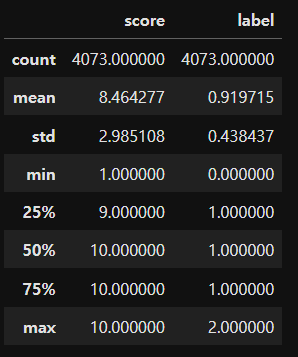
🐤 기초통계 확인 : 이상 데이터 확인
- 이상치 확인 : score는 0~10 / label은 0~2
df_org.describe()
🐤 평점(score) 현황 데이터 확인
- value_counts() : 항목 별 갯수
df_org["score"].value_counts()

🐤 긍정/부정 현황 데이터 확인
df_org["label"].value_counts()

🐤 중복데이터 확인하기
① keep = False : 중복된 모든행 체크(중복이 있으면 True, 없으면 False)
df_org[df_org.duplicated(keep = False) == True]

② 중복데이터 확인하기( 원본 제외하고 )
df_org[df_org.duplicated() == True]

③ 중복 중에 하나는 제외하고 나머지 중복만 추출(40개만 삭제)
- drop_duplicates() : 중복 하나만 남기고 삭제
df_new = df_org.drop_duplicates()
len(df_new)
기존 4073개 >> 삭제 후 4033개
웹크롤링 - 데이터 탐색하기
🐤 영화 제목만 추출하기
- unique() : numpy의 배열 타입으로 반환함
df_new["title"].unique()

🐤 영화 제목별 리뷰갯수 현황 확인하기
df_new["title"].value_counts()

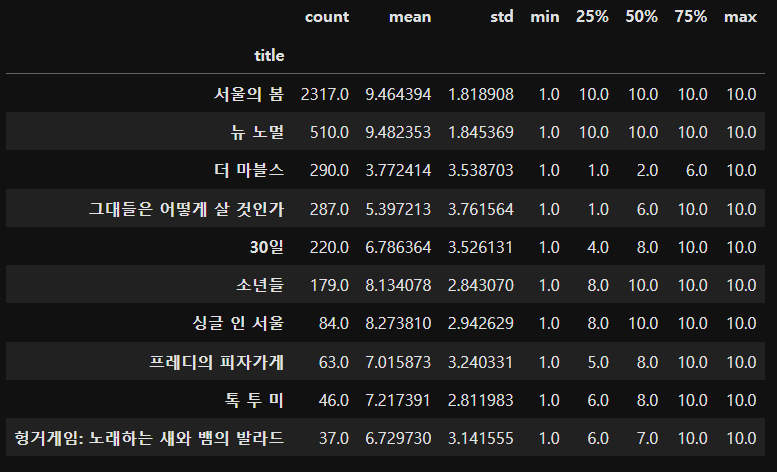
🐤 각 영화별 평점 기초통계 확인하기
① 영화제목별 평점에 대한 그룹집계하기
- groupby("title") : 영화제목별로 묶기
- ["score"] : 영화제목별 score 리스트 값(숫자)
- describe() : 기초통계 확인
movie_info = df_new.groupby("title")["score"].describe()
② 기초통계 행단위 데이터 내림차순으로 정렬하기
movie_info = movie_info.sort_values(by=["count"], axis=0, ascending=False)
movie_info
웹크롤링 - 데이터 시각화
🐤 시각화 라이브러리
import matplotlib.pyplot as plt
🐤 폰트 설정 라이브러리
from matplotlib import font_manager, rc
🐤 한글 폰트 설정
plt.rc("font", family = "Malgun Gothic")
🐤 마이너스 기호 설정
plt.rcParams["axes.unicode_minus"] = False
🐤 영화별 평점평균 시각화
※ array() : 넘파이(numpy)에서 사용하는 배열(파이썬의 리스트와 동일)
단, 하나의 타입만 저장 가능합니다.
이외 사용법은 파이썬의 리스트와 동일
① 평점평균 계산을 위한 라이브러리 사용
import numpy as np
② 영화제목을 리스트 타입으로 받아오기 ( array → list )
- unique() : numpy의 배열 타입으로 반환함
- tolist() : 파이썬의 리스트 타입으로 변환하는 함수
movie_title = df_new["title"].unique().tolist()
movie_title

🐤 영화별 평점 평균 추출하기
① 평점평균값을 저장할 딕셔너리 변수 선언
avg_score = {}
② 반복문
### 제목들 하나씩 반복하기
for m_title in movie_title:
### 평점 평균 계산하여 딕셔너리에 넣기
avg = df_new[df_new["title"] == m_title]["score"].mean()
print(f"평점평균 : {avg}")
### 딕셔너리에 담기
# key는 제목, value는 평점평균값
avg_score[m_title] = avg
print(f"딕셔너리 최종값 : {avg_score}")

막대그래프 그리기
- 영화별 평점평균 시각화
: 영화별 평점 평균이 가장 큰 영화는 orange색으로, 나머지는 lightgrey 색으로 표현
- array_str() : 문자열로 변환하는 함수
where() : 파이썬에서 if문과 동일한 조건문
where(조건, 참, 거짓) : 조건이 참이면 첫번째 값, 거짓이면 두번째 값 처리
# 그래프 너비와 높이 지정
plt.figure(figsize=(10,5))
# 그래프 제목
plt.title("영화별 평점 평균 막대그래프", fontsize = 17, fontweight="bold")
### 각 영화별 평점 평균 막대그래프 그리기
for k,v in avg_score.items():
# 컬러값 지정하기
color = np.array_str(np.where(v == max(avg_score.values()), "orange", "lightgrey"))
# print(color)
# 막대그래프 그리기
plt.bar(k, v, color=color)
### 막대그래프 상단에 평점평균 텍스트 표시하기
# "%.2f"%v : 표시할 값 (소수점 2자리까지 표현)
plt.text(k, v, "%.2f"%v, horizontalalignment = "center", verticalalignment = "bottom")
### x축과 y축 제목 넣기
plt.xlabel("영화 제목", fontweight="bold")
plt.ylabel("평점 평균", fontweight="bold")
### x축 y축 값 각도 조절하기
plt.xticks(rotation = 75)
### 그래프를 이미지로 저장시키기
# savefig() 함수는 plt.show() 전에 수행되어야 한다.
plt.savefig("./img/영화별 평점 평균 막대그래프.png")
plt.show()

점(분포)그래프 그리기
- 각 영화별 평점 분포도 그리기
: 하나의 큰 그래프 안에 10개의 그래프를 넣어서 표현 → 서브플롯(subplot)
- fig : 큰 그래프 정보
- axs : 5행 2열의 내부 그래프 공간 정보 ( 공간정보 리스트로 가지고 있음 )
- 5행 2열의 subplot 생성하여 구현하기
- subplots(행갯수, 열갯수, 전체 그래프 크기)
- flatten() : 틀 정렬하기 -> 5행 2열의 틀을 정렬해 놓기
- arange(num) : 0부터 num까지의 값을 순차적으로 쪼개서 범주를 만들어줌
- set_title() : 각 그래프 제목 지정
- "o" : 점으로 표현하는 마커 기호
"x" : x로 표현하는 마커 기호
- axhline() : 각 subplot 공간에 수평선(y축) 그리기
(넣어줄 y축 값, 색상지정, 라인스타일 지정 linestyle= 실선"-" or 점선 "--" )
- savefig(경로) : 이미지 저장함수
### 서브플롯 생성 (행갯수, 열갯수, 전체 그래프 크기)
fig, axs = plt.subplots(5, 2, figsize=(15, 25))
### 여러개의 그래프를 for문을 이용해서 표현하고자 할때 아래 먼저 수행
axs = axs.flatten()
### 각 그래프를 행렬 공간의 subplot에 넣기
for title, avg, ax in zip(avg_score.keys(), avg_score.values(), axs):
# print(f"{title} / {avg} / {ax}")
### x축에는 영화 리뷰 갯수, y축에는 평점평균
### 리뷰 개수 추출하기(범주가 없으니까 arange사용!)
num_reviews = len( df_new[df_new["title"] == title] )
x = np.arange(num_reviews)
# print(f"x ----------> {x}")
### y축에는 평점 추가(이미 범주가 0~10까지 정해져 있음)
y = df_new[df_new["title"] == title]["score"]
# print(f"y ----------> {y}")
##### 해당 공간을 지정해줘야함!!!(ax.~~)
### 각 그래프에 제목 넣기
subtitle = f"{title} ({num_reviews}명)"
ax.set_title(subtitle, fontsize=15, fontweight="bold")
### 점 그래프 그리기
ax.plot(x, y, "o")
### 각 영화별 평점평균을 빨강색 점선으로 표시하기
ax.axhline(avg, color="red", linestyle="--")
### 이미지 저장
plt.savefig("./img/각 영화별 평점 분포도.png")
plt.show()

원형 그래프 그리기
- 긍정, 부정, 기타에 대한 원형 그래프 시각화하기
: 비율이 가장 높은 경우 : pink색, 두번째 : gold색, 세번째 : whitesmoke색으로 표현 → 서브플롯(subplot)
- ax.pie(values,
# 원형그래프에 표시할 라벨 지정
labels = labels,
# 원형그래프에 표시할 값의 소수점 자리수 지정 (% : 퍼센트로 표시해라 ;빈도율)
autopct = "%1.1f%%",
# 원형그래프 각 영역의 색상 지정
colors = colors,
# 그림자 효과 지정하기
shadow = True,
# 그래프의 시작위치를 수직
startangle = 90)
### 서브플롯 생성 (행갯수, 열갯수, 전체 그래프 크기)
fig, axs = plt.subplots(5, 2, figsize=(15, 25))
### 여러개의 그래프를 for문을 이용해서 표현하고자 할때 아래 먼저 수행
axs = axs.flatten()
### 빈도 비율별 색상 정의
colors = ["pink", "gold", "whitesmoke"]
### 라벨 정의 (딕셔너리)
labels_dict = {0 : "부정(1~4점)", 1 : "긍정(8~10점)", 2 : "기타(5~7점)"}
### 긍정/부정에 대한 원형 그래프 그리기
# avg_score.keys : 10개의 제목 가져오기
# axs : 5행2열의 10개 공간 리스트
for title, ax in zip( avg_score.keys(), axs ):
### 영화별 건수 필터링하기 - 조건문 넣어주기
num_reviews = len(df_new[df_new["title"] == title])
# print(f"num_reviews = {num_reviews}")
### label 컬럼의 범주별로 갯수 필터링하기
values = df_new[df_new["title"] == title]["label"].value_counts()
# print(f" values = {values}")
### 원형 그래프에 표시할 라벨값 정의하기
# 영화별로 긍정 또는 부정 또는 기타 중에 하나라도 없으면 처리가 필요함
label_list = df_new[df_new["title"]==title]["label"].unique()
labels = []
for k in label_list:
### 영화별 실제 존재하는 긍정/부정/기타 라벨 정의하기
labels.append(labels_dict[k])
### 각 그래프 제목 넣기
ax.set_title(f"{title} ({num_reviews}명)", fontsize=15)
### 원형(pie) 그래프 그리기
ax.pie(values,
# 원형그래프에 표시할 라벨 지정
labels = labels,
# 원형그래프에 표시할 값의 소수점 자리수 지정 (% : 퍼센트로 표시해라 ;빈도율)
autopct = "%1.1f%%",
# 원형그래프 각 영역의 색상 지정
colors = colors,
# 그림자 효과 지정하기
shadow = True,
# 그래프의 시작위치를 수직
startangle = 90)
### 이미지 저장
plt.savefig("./img/긍정_부정_원형그래프_시각화.png")
plt.show()

웹크롤링 - 파일로 저장
🐤 최종 전처리된 데이터는 파일로 관리하기
- 파일명 df_new.csv, 인덱스는 포함하지 않기
- 저장위치 : data 폴더
save_path = "./data/df_new.csv"
df_new.to_csv(save_path, index=False)

'Back-End > 데이터베이스' 카테고리의 다른 글
| [DB] 데이터프레임 정리 - 행/열 합치기, 결측치, 중복값, 이상치 처리 (3) | 2023.12.05 |
|---|---|
| [DB] 워드클라우드 시각화 - KoNLPY, Okt, Counter, WordCloud (6) | 2023.12.05 |
| [DB] 데이터 수집 - 웹크롤링(selenium) (1) | 2023.12.04 |
| [DB] 데이터베이스 실습 - 버스교통카드 데이터 전처리 시각화(히트맵, 막대그래프, 선그래프) (2) | 2023.11.30 |
| [DB] 데이터베이스 실습 - 버스교통카드 데이터 수집 가공 (0) | 2023.11.29 |




