데이터 파일 다운로드👻
[포항시 BIS 교통카드 사용내역 데이터 수집]
1. URL : 국가교통 데이터 오픈마켓
2. 로그인 후 "포항시 BIS 교통카드 사용내역" 검색
3. 상품 다운로드 >> 200개씩 보기 >> 전체선택 >> 파일 다운로드 >> 80개 압축파일 다운
데이터 가져오기
1. 라이브러리 정의하기
import pandas as pd
2. 사용할 데이터 읽어들이기
- 데이터프레임 변수명 : df_bus_card_tot
file_path = './01_data/all/df_bus_card_tot.csv'
df_bus_card_tot = pd.read_csv(file_path)
print("갯수 : ", len(df_bus_card_tot))
df_bus_card_tot.head()
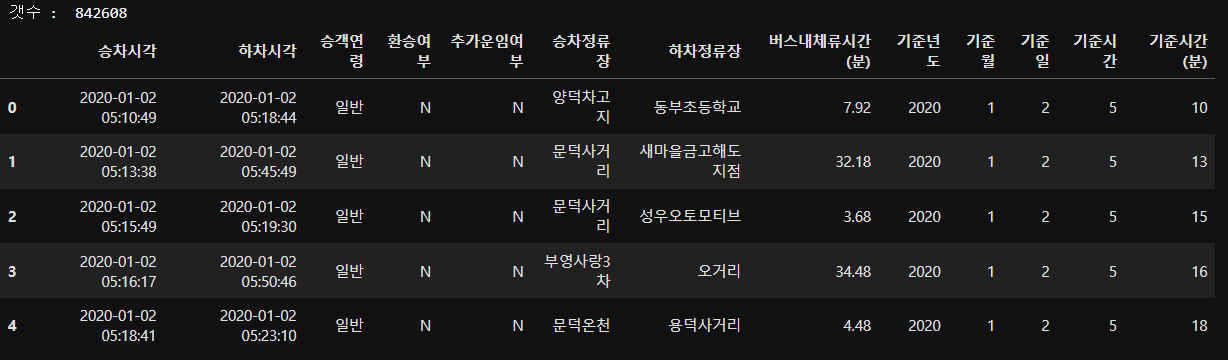
3. 데이터 정보확인
- 결측치 있는지 확인 : 승객연령
df_bus_card_tot.info()

4. 기초통계 확인하기
- 이상치 있는지 확인 : min이 (-)값 있는지
df_bus_card_tot.describe()

5. 데이터 확인
df_bus_card_tot
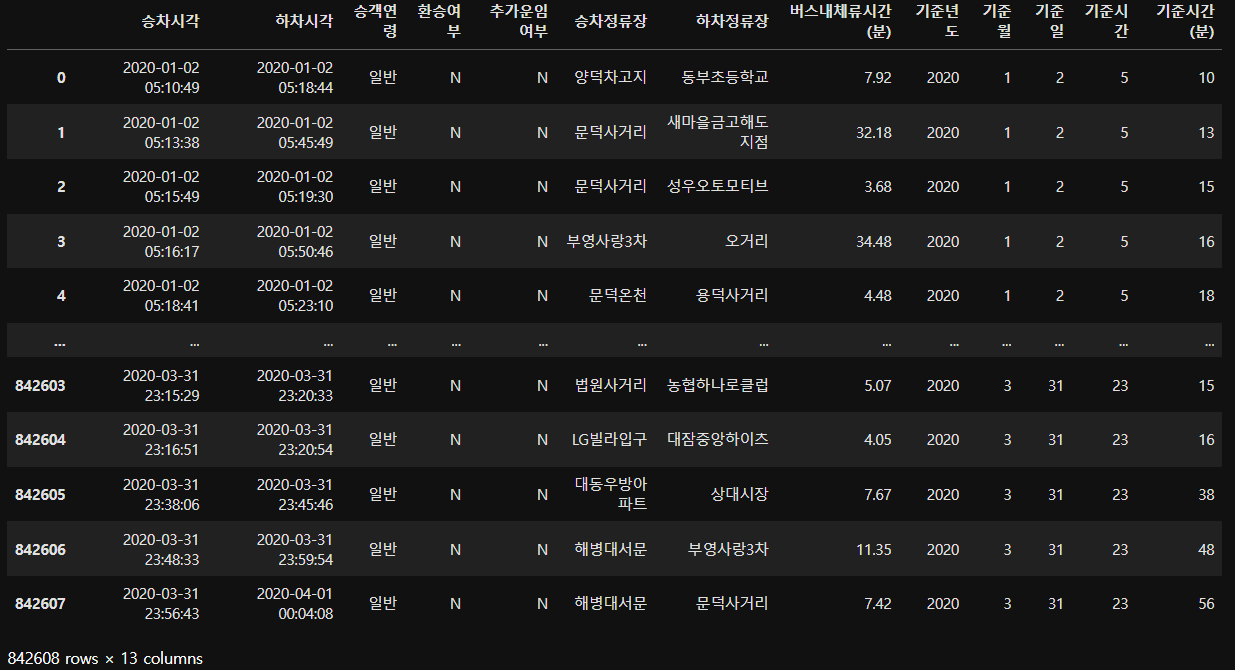
데이터 시각화 : 히트맵
1. 시각화 라이브러리
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
2. 폰트 처리 라이브러리
- 그래프 내에 한글이 포함된 경우 폰트 처리가 필요함
- 한글 깨짐 방지를 위해서
- 폰트 환경설정 라이브러리
from matplotlib import font_manager, rc
### 윈도우
plt.rc("font", family = "Malgun Gothic")
### MAC
#plt.rc("font", family = "AppleGothic")
### 그래프 내에 마이너스( - ) 표시 기호 적용하기
plt.rcParams["axes.unicode_minus"] = False
※ (추가) 운영체제 확인을 위한 라이브러리 : import platform
3. 기준월 및 기준일자별 버스 이용량 시각화 분석
- 사용할 컬럼 : 기준월, 기준일, 승객연령
- 사용할 집계함수 : count
- 이용량 집계를 위한 함수 : pivot_table() -> 히트맵 시각화시 데이터 생성
- 사용할 그래프 : 히트맵(heatmap)
- 히트맵 형태 (3가지 정보 필요 x축, y축, 값)
### 데이터 count 집계하기
# x축 : columns
# y축 : index
# 집계 : count(승객연령)
df_pivot = df_bus_card_tot.pivot_table(index = "기준월",
columns = "기준일",
values = "승객연령",
aggfunc = "count")
df_pivot

4. 결측치(NaN) 처리하기
- NaN인 데이터 값을 바꾸기
- 단 타당성이 있어야 한다. EX) 2월은 29일 까지 밖에 없으므로 30,31 은 NaN일 수 밖에 없음 (따로 작성함)
- 단 타당성 없는 결측치는. EX) 3월 22일~24일 (데이터 수집한 회사에 문의해봐야함, 왜 데이터가 없나요?)
==> 이런경우 3월 비어있는 값의 (전날 값 + 다음날 값)의 평균을 넣을 수 있다. (내용을 작성해놓기)
### 모든 결측치(NaN)는 0으로 대체하기
df_pivot = df_pivot.fillna(0)
df_pivot
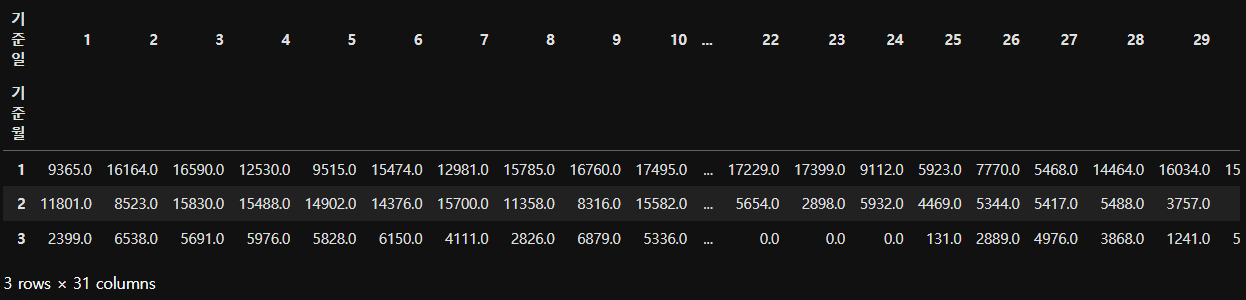
5. 히트맵(heatmap) 시각화
- 그래프 생성
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준월 및 기준일자별 버스 이용량 분석")
### 그래프 보여줘
plt.show()
- 히트맵 생성
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준월 및 기준일자별 버스 이용량 분석")
### 히트맵 그리기 : 히트맵은 seaborn 라이브러리에 있음
# annot : False는 집계값 숨기기, True는 집계값 보이기
# fmt : ".0f" 는 소수점 1자리 까지 보이기
# cmap : color 맵, color
sns.heatmap(df_pivot, annot=False, fmt=".0f", cmap="rocket_r")
### 그래프 보여줘
plt.show()

< 해석 >
- 1월~3월까지의 이용량을 분석한 결과 1월에 가장많은 이용량을 나타내고 있으며,
2월에서 3월로 가면서 이용량이 점진적으로 줄어들고 있는것으로 확인됨.
- 1월에 이용량이 많은 이유는 포항시의 특성상 외부에서 관광객의 유입에 따라,
버스를 이용하는 사람들이 많을 것으로 예상됨.
- 이에 따라, 포항시 관광객에 대한 데이터를 수집하여 해당 년월에 대한 데이터를 비교 분석해볼 필요성이 있음.
3 - 1 . 기준일 및 기준시간별 버스 이용량 시각화 분석
- 사용할 컬럼 : 기준일, 기준시간, 승객연령
- 사용할 집계함수 : count
- 이용량 집계를 위한 함수 : pivot_table() -> 히트맵 시각화시 데이터 생성
- 사용할 그래프 : 히트맵(heatmap)
- 히트맵 형태 (3가지 정보 필요 x축, y축, 값)
### 데이터 count 집계하기
# x축 : columns
# y축 : index
# 집계 : count(승객연령)
df_pivot = df_bus_card_tot.pivot_table(index = "기준일",
columns = "기준시",
values = "승객연령",
aggfunc = "count")
df_pivot
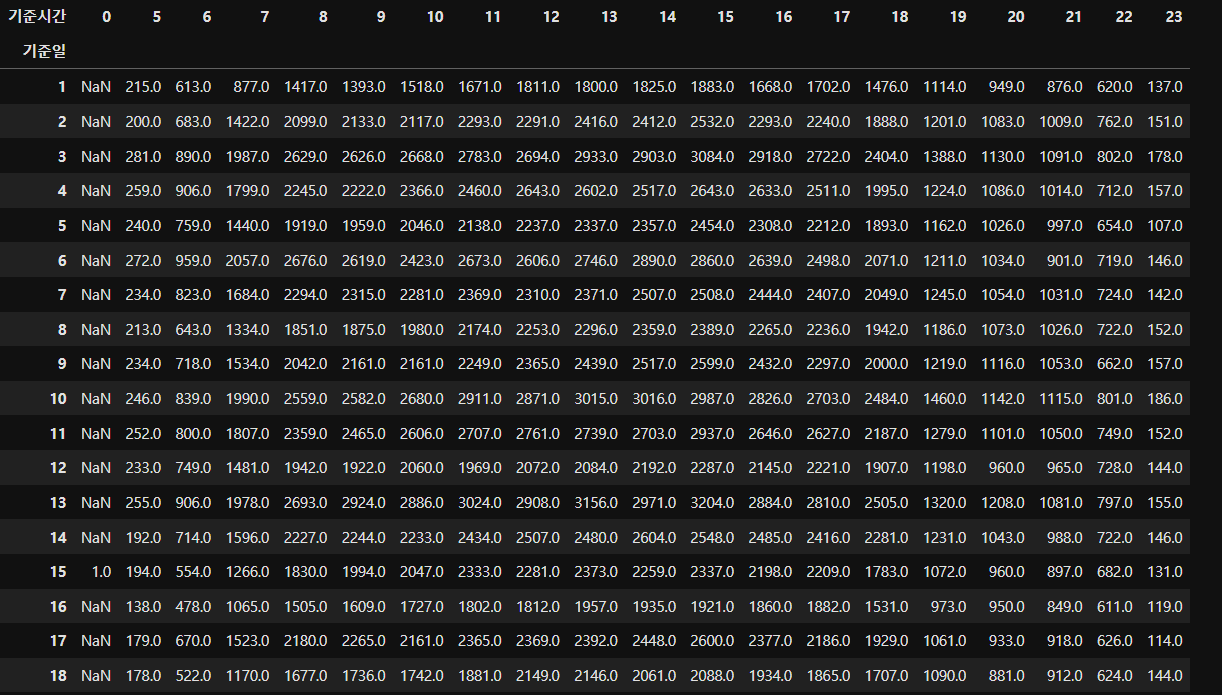
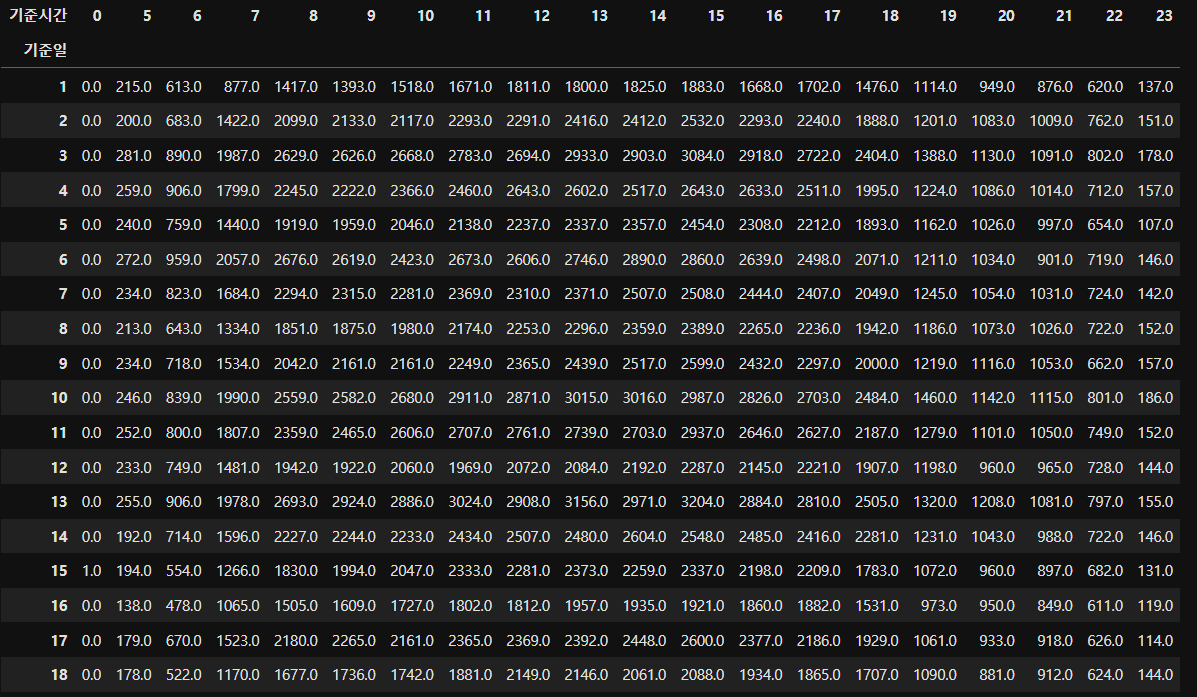
- NaN인 데이터 값을 0으로 바꾸기 (12시에는 버스가 안다니므로 count가 안됨)
df_pivot = df_pivot.fillna(0)
df_pivot
- 히트맵 생성
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준일 및 기준시간별 버스 이용량 분석")
### 히트맵 그리기 : 히트맵은 seaborn 라이브러리에 있음
# annot : False는 집계값 숨기기, True는 집계값 보이기
# fmt : ".0f" 는 소수점 1자리 까지 보이기
# cmap : color 맵
cmap = sns.diverging_palette(220,10,as_cmap=True)
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap=cmap)
### 그래프 보여줘
plt.show()

- 정보 확인
# unique() : 고유값만 뽑아오기
df_bus_card_tot["승객연령"].unique()

< 해석 >
- 버스 이용량에 대한 분석결과,
- 일반적으로 출/퇴근 시간에 많아야할 버스이용량이, 포항시의 경우 오후 시간대에 이용량이 밀집되어 있음.
- 특히, 오후 1시, 3시에 높은 이용량을 나타내고 있음.
- 이는 출/퇴근 시간에 자가 차량을 이용하는 사람이 많을 수도 있다는 예상을 할 수 있으며,
인구 분포가 노령인구가 많기에 오후에 이용자가 많을 수도 있을 수 있음
- 따라서, 포항시 인구현황 데이터, 경제활동인구 분석을 통해 비교 분석이 가능할 것으로 예상됨
- 또한, 해당 이용량이 높은 시간대에 노선을 확인하여 특성 확인도 필요할 것으로 예상됨.
3 - 2 . 기준시간 및 분별 버스 이용량 시각화 분석
### 값이 적은게 열로 가도록 생성!!
df_pivot = df_bus_card_tot.pivot_table(index = "기준시간(분)",
columns = "기준시간",
values = "승객연령",
aggfunc = "count")
### 결측치 값 0으로 바꾸기
df_pivot = df_pivot.fillna(0)
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준시간 및 분별 버스 이용량 분석")
### 히트맵 그리기
cmap = sns.diverging_palette(220,10,as_cmap=True)
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap=cmap)
### 그래프 출력
plt.show()

< 해석 >
- 출/퇴근 시간대의 버스이용량을 볼 때 오전 7시 55분 ~ 8시 10분 사이에 이용량이 많은 것으로 보이며,
- 퇴근 시간대의 경우에는 오후 6시 ~ 6시 20분까지 이용량이 많은 것으로 보임
- 특히 오후 3시 20분까지 버스 이용량이 매우 크게 나타나고 있음
- 오후 시간대 이용자에 대한 추가 확인은 필요할 것으로 보임
3 - 3 . 기준일 및 시간별 버스내체류시간(분) 시각화 분석
### 값이 적은게 열로 가도록 생성!!
# 버스체류시간을 비교해야하니까 count가 아닌 mean(평균)으로 주었다.
df_pivot = df_bus_card_tot.pivot_table(index = "기준일",
columns = "기준시간",
values = "버스내체류시간(분)",
aggfunc = "mean")
### 결측치 값 0으로 바꾸기
df_pivot = df_pivot.fillna(0)
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준일 및 시간별 버스내체류시간(분) 시각화 분석")
### 히트맵 그리기
# fmt=".0f" : 소수점 없애고 값을 나타냈다.
cmap = sns.diverging_palette(220,10,as_cmap=True)
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap=cmap)
### 그래프 출력
plt.show()
"""
(내 해석)
- 시간별 버스내체류시간을 분석해본 결과 오전 7시 ~ 오후 6시까지 체류시간이 긴 것으로 확인 된다.
- 이는 사람들의 활동시간이기 때문인것으로 추정되고
- 특히 오후 5시대에 버스내 체류시간이 매우 크게 나타나고 있음
- 이는 퇴근시간대 교통정체 현상으로 버스내 체류가 길어지는 것으로 추측된다.
"""
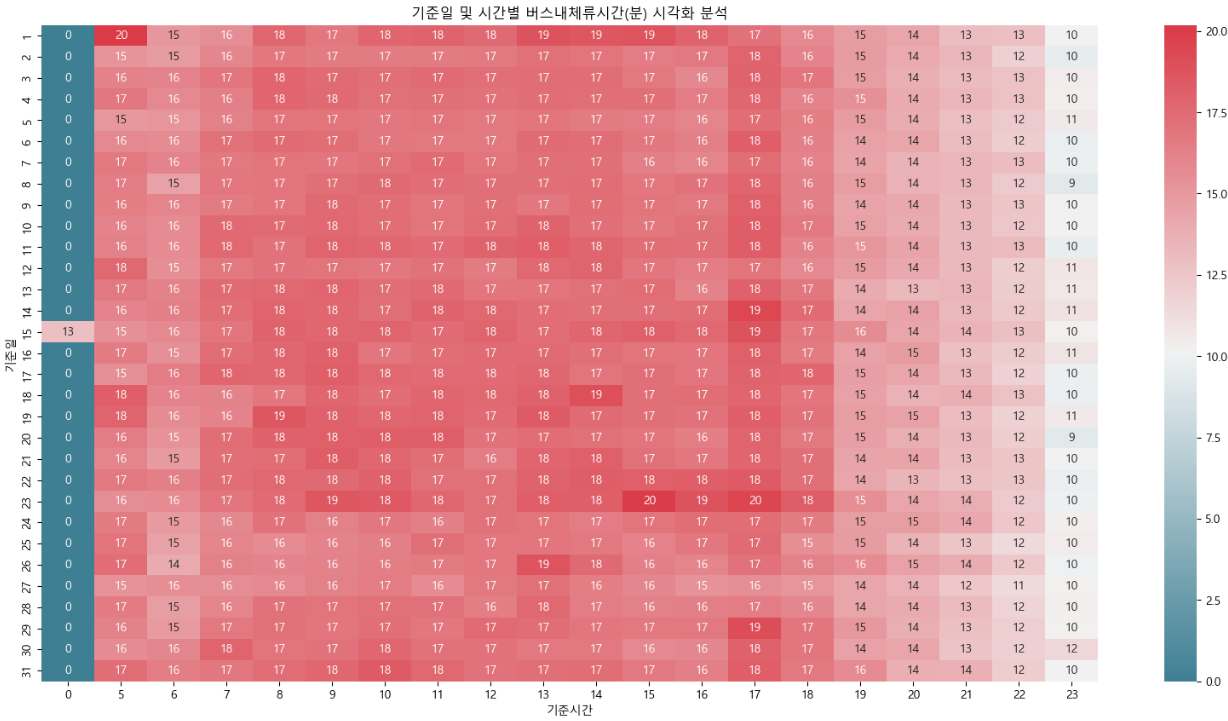
< 해석 >
- 매월 1일에 장거리 이용자가 다소 분포하고 있으며,
- 오전 5시부터 8시를 전후로 장거리 이용자가 증가하고 있음
- 오후 5시에 장거리 이용자가 매우 많게 나타남
- 이는 포항시 주변 상권(경제활동인구)의 출/퇴근 시간의 영향을 받을 수도 있을 것으로 예상됨
- 오전 7시 이후로는 장거리 이용자는 보편적으로 나타나고 있으며,
위에서 분석한 기준일 및 시간별 이용량 분석에서 확인한 바와 같이 오후 7시 이후의 버스 이용량도 급격하게 줄어드는 것으로 보아,
저녁 시간 버스 이용이 현저히 낮은것으로 여겨짐
- 장거리 이용자가 많은 시간대에 급행버스의 도입에 대한 추가 확인은 필요할 것으로 여겨짐
이쁜 cmap 사용하기 🪄
1. 시각화 라이브러리
import matplotlib.cm
2. cmap 적용
- cmap 추천 : "GnBu", "Pastel1", "gnuplot2","rainbow", "spring", "PuRd", "BuPu"
df_pivot = df_bus_card_tot.pivot_table(index = "기준일",
columns = "기준시간",
values = "버스내체류시간(분)",
aggfunc = "mean")
### 결측치 값 0으로 바꾸기
df_pivot = df_pivot.fillna(0)
### 그래프 전체 너비, 높이 설정
plt.figure(figsize=(20, 10))
### 그래프 제목 넣기
plt.title("기준일 및 시간별 버스내체류시간(분) 시각화 분석")
### 히트맵 그리기
sns.heatmap(df_pivot, annot=True, fmt=".0f", cmap="GnBu")
### 그래프 출력
plt.show()
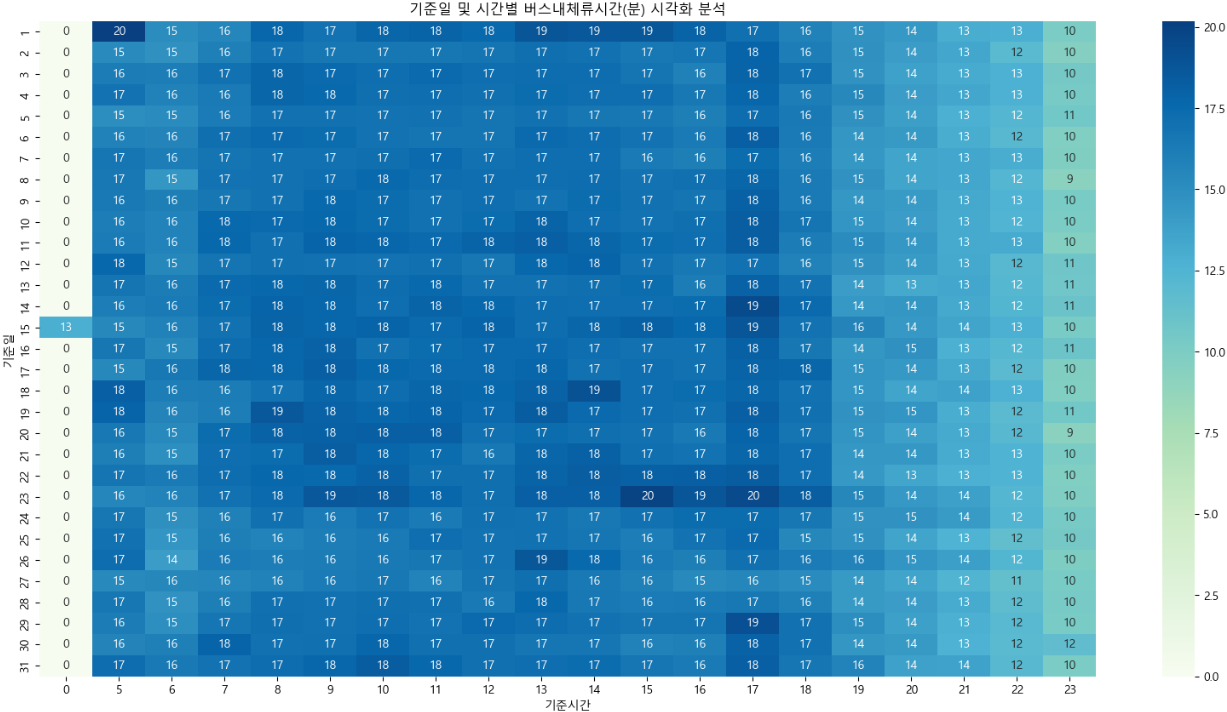

데이터 시각화 : 막대그래프
시간대 및 승객연령별 버스내체류시간(분) 시각화 (막대그래프)
- 데이터프레임 생성
- 필요한 데이터 : 기준시간, 승객연령, 버스내체류시간(분)
df_temp = pd.DataFrame()
df_temp["기준시간"] = df_bus_card_tot["기준시간"]
df_temp["승객구분"] = df_bus_card_tot["승객연령"]
df_temp["버스내체류시간"] = df_bus_card_tot["버스내체류시간(분)"]
df_temp

1. 빈도 확인하기
- 승객 빈도 확인하기
- value_counts()
df_temp["승객구분"].value_counts()

2. 그룹화 하기
- groupby()
df_temp2 = df_temp.groupby(["기준시간", "승객구분"])
df_temp2

< groupby 이후의 head()의 역할 >
- 그룹단위로 조회됨
- head(1) : 각 그룹의 첫번째 값을 조회시켜 준다.
- 그룹화 후 head(1)은 그룹단위로 1개가 됨.
따라서 한 행만 출력되는게 아니라 첫번째 그룹이 다 출력됨
df_temp2.head(1)

- 그룹화 + 평균값 출력
df_temp2 = df_temp.groupby(["기준시간", "승객구분"]).mean()
df_temp2

- 그룹화 + 합계 출력
df_temp2 = df_temp.groupby(["기준시간", "승객구분"]).sum()
df_temp2

- 그룹화 + 합계 출력 + index설정 + 정렬(내림차순)
df_temp2 = df_temp.groupby(["기준시간", "승객구분"], as_index = False).sum()
df_temp2 = df_temp2.sort_values(by=["버스내체류시간"], ascending=False)
df_temp2

3. 데이터의 행과 열을 교환하기
- transpose()
df_temp2.transpose()

4. 그래프 시각화 하기
- barplot : 막대그래프 ( x값, y값, hue값, 데이터프레임)
- hue : x축 및 y축을 기준으로 비교할 대상 컬럼 지정 (범주형 데이터를 보통 사용 ;빈도)
fig = plt.figure(figsize=(25,10))
plt.title("시간 및 승객구분별 버스내 체류시간(분단위) 분석")
sns.barplot(x="기준시간", y="버스내체류시간", hue="승객구분", data=df_temp2)
plt.show()

5. histplot 시각화
- histplot 시각화 : 두개 그래프 조합 (보통 밀도 그래프라고 한다.)
- bins : 사용할 막대의 최대 개수
- kde = True : 막대그래프에 밀도 선 그리기
- hue : 범주 데이터
- multiple = "stack" : 여러 범주를 하나의 막대에 표현하기
- stat = "density" : 비율로 표시
- shrink : 막대 너비 0.6은 원본 100%에서 60% 축소한 너비 사이즈
plt.figure(figsize=(12,4))
plt.title("시간 및 승객구분별 버스내 체류시간(분단위) 분석")
sns.histplot(data = df_temp2,
x = "기준시간",
bins = 30,
kde = True,
hue = "승객구분",
multiple = "stack",
stat = "density",
shrink = 0.6)
plt.show()

데이터 시각화 : 선 그래프
승하차정류장별 버스내체류시간(분) 상위 30건 시각화 분석
- 구간(승차정류장 ~ 하차정류장) 까지의 버스내 체류시간을 이용하여 체류시간이 많은 구간을 확인하기
1. 구간(승차정류장 ~ 하차정류장)별 버스내체류시간(분) sum() 그룹화 하기
2. 내림차순 정렬
3. 상위 30개 추출
df_bus_card_tot

1. 데이터프레임 만들기
- 승하차 구간 만들기
df_temp = pd.DataFrame()
df_temp["승하차정류장"] = df_bus_card_tot['승차정류장'] + ' - ' + df_bus_card_tot['하차정류장']
df_temp["버스내체류시간"] = df_bus_card_tot["버스내체류시간(분)"]
df_temp
2. 승하차정류장별 체류시간 그룹화하기
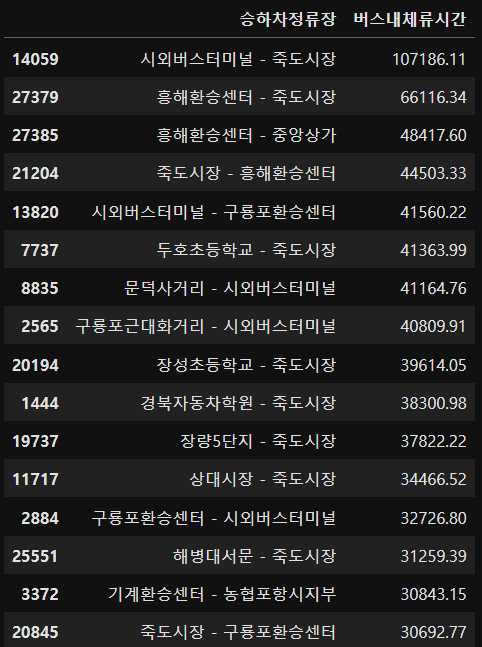
df_temp_gp = df_temp.groupby(["승하차정류장"], as_index=False).sum()
df_temp_gp = df_temp_gp.sort_values(by=["버스내체류시간"], ascending=False)
#상위 30개 추출
df_temp_30=df_temp_gp.head(30)
df_temp_30
3. 선그래프 시각화하기
- x축 및 y축 제목 넣기 : xlabel()
- 축의 값의 기울기를 이용하여 조정하기 : xticks(), yticks()
- 격자선 표시하기 : grid(True)
plt.figure(figsize=(12,4))
plt.title("승하차정류장별 버스내 체류시간 분석")
### 선 그래프
plt.plot(df_temp_30["승하차정류장"], df_temp_30["버스내체류시간"])
### x축 및 y축 제목 넣기
plt.xlabel("승하차정류장")
plt.ylabel("버스내체류시간(분)")
### x축의 값의 기울기를 이용하여 조정하기
# xticks() : x축을 컨트롤하는 함수
# yticks() : y축을 컨트롤하는 함수
plt.xticks(rotation=90)
### 격자선 표시하기
plt.grid(True)
plt.show()

'Back-End > 데이터베이스' 카테고리의 다른 글
| [DB] 데이터 전처리 및 시각화 - 웹크롤링(selenium), 점(분포) 그래프, 원형 그래프 (10) | 2023.12.04 |
|---|---|
| [DB] 데이터 수집 - 웹크롤링(selenium) (1) | 2023.12.04 |
| [DB] 데이터베이스 실습 - 버스교통카드 데이터 수집 가공 (0) | 2023.11.29 |
| [DB] 데이터베이스 연결 - pymysql 라이브러리 사용 (3) | 2023.11.29 |
| [DB] 데이터베이스 테이블에 저장하기, 설계하기 (DB 연결, 저장, 자원반환) (2) | 2023.11.28 |




