데이터 가져오기 🐥
"""라이브러리 정의"""
import pandas as pd
"""
- 데이터프레임 변수 : data
- 데이터 읽어들이기
"""
data = pd.read_csv("./data/01_회귀_OOOO예측_데이터셋_Row_1000.csv")
data.head(1)
data.info()
data.describe()
"""독립변수(X)와 종속변수(y)로 분리하기"""
X = data.iloc[:, :-1]
y = data["OOOO"]
print(X, y)
X.shape, y.shape
"""
정규화 하기
- X_scaled 변수명 사용
"""
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
print(X_scaled.shape)
X_scaled
"""
훈련 : 테스트 데이터로 분류하기(8:2)
- 사용변수 : X_train, X_test, y_train, y_test
"""
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y,
test_size=0.2,
random_state=42)
print(f"{X_train.shape}, {y_train.shape}")
print(f"{X_test.shape}, {y_test.shape}")
### X_train의 열의 갯수 : 4
X_train.shape[1]
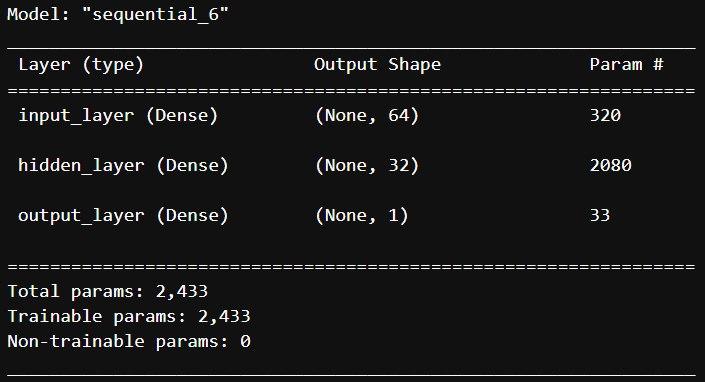
심층신경망(DNN)🐥
< 모델 및 계층 생성하기 >
- 모델 변수명 : model
- 계층 구조 : 입력계층 → 출력크기 64, 활성화함수 relu, 입력개수 4
: 은닉계층 → 출력크기 32, 활성화함수 relu
: 출력계층 → 출력크기 1, 활성화함수 linear
- 계층 구조 확인하기
"""모델 및 계층 생성하기"""
import tensorflow as tf
from tensorflow import keras
"""실행 결과를 동일하게 하기 위한 처리(완전 동일하지 않을 수도 있음)"""
tf.keras.utils.set_random_seed(42)
"""연산 고정"""
tf.config.experimental.enable_op_determinism()
model = keras.Sequential()
model.add(
keras.layers.Dense(64, activation="relu", input_shape=(X_train.shape[1], ), name="input_layer")
)
model.add(
keras.layers.Dense(32, activation="relu", name="hidden_layer")
)
"""회귀의 경우에는 출력계층에 사용하는 활성화함수는 linear를 적용"""
model.add(
keras.layers.Dense(1, activation="linear", name="output_layer")
)
model.summary()
* 회귀의 경우에는 출력계층에 사용하는 활성화함수는 linear를 적용
* 적용방법
- activation을 사용하지 않으면 디폴트값으로 linear이 적용됨
- activation = None 적용해도됨
- activation = 'linear' 적용(보통 정의해 줍니다.)
회귀 모델 🐥
""" 모델 설정하기
- 옵티마이저 adam 적용
- 손실함수(loss) : mse(mean_squared_error)사용
"""
model.compile(optimizer="adam", loss="mean_squared_error")
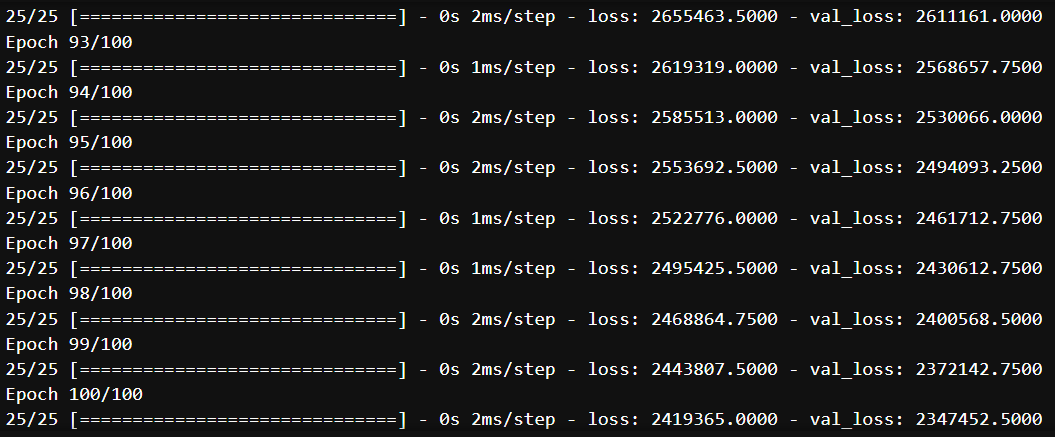
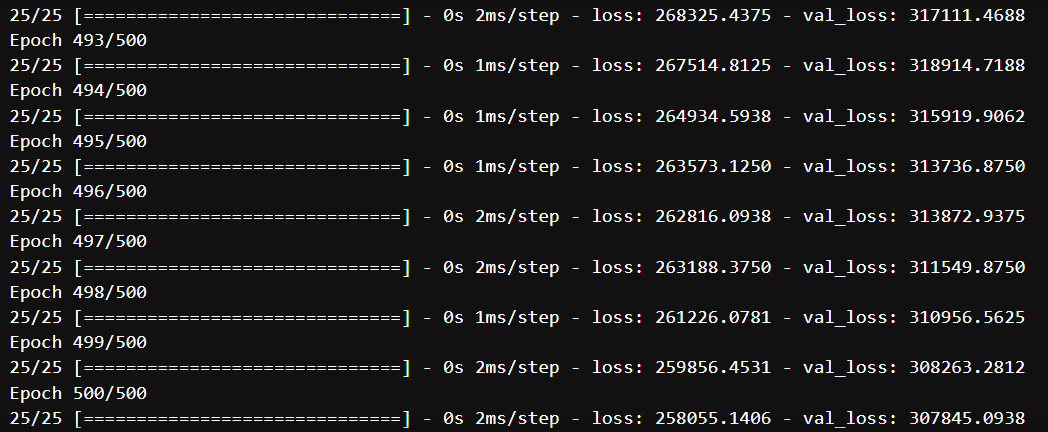
""" 훈련시키기
- 반복횟수 100회 → 500회
- 훈련 및 검증 동시에
"""
history=model.fit(X_train, y_train, epochs=500, verbose=1, validation_data=(X_test, y_test))
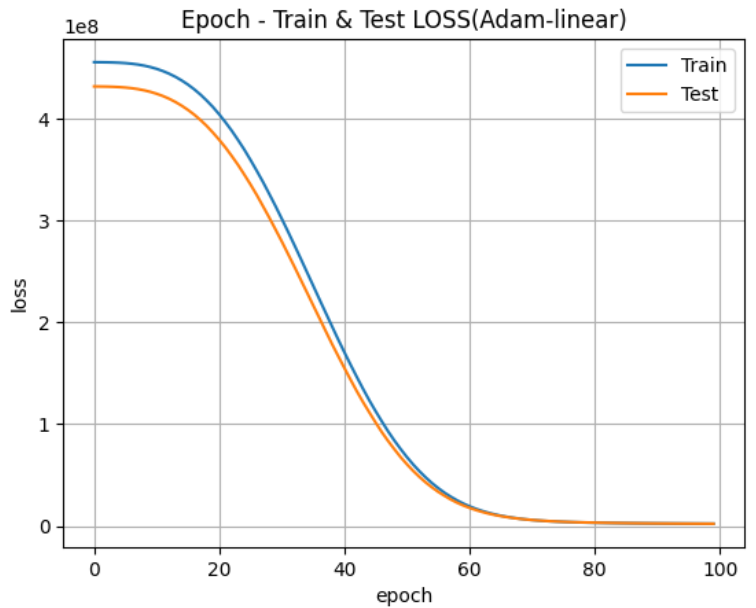
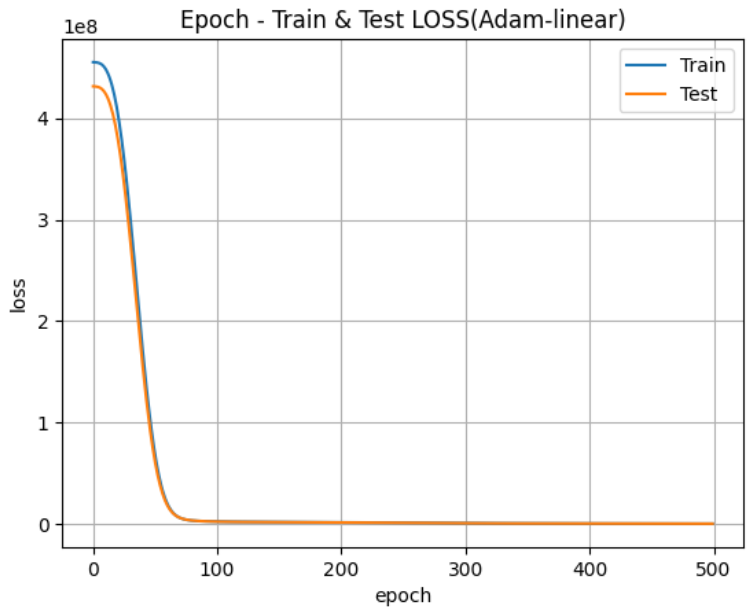
훈련 및 검증에 대한 시각화하기 🐥
import matplotlib.pyplot as plt
""" 훈련과 검증에 대한 곡선"""
plt.title("Epoch - Train & Test LOSS(Adam-linear)")
plt.plot(history.epoch, history.history["loss"])
plt.plot(history.epoch, history.history["val_loss"])
plt.xlabel("epoch")
plt.ylabel("loss")
plt.grid()
plt.legend(["Train", "Test"])
"""이미지로 저장 시키기"""
plt.savefig(f"./saveFig/Epoch-Train_Test_loss(Adam-linear).png")
plt.show()
↓
모델 예측 및 성능평가하기 - MSE, R2-score 🐥
"""모델 예측하기"""
y_pred = model.predict(X_test)
y_pred
"""
성능평가하기
- MSE(오차)와 R2-score(설득력) 평가하기
"""
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE : {mse} / R2-score : {r2}")
MSE : 307845.0464585237 / R2-score : 0.9973264818392876
X_test 0번째에 독립변수를 이용하여 종속변수 예측해 보기 🐥
* X_test[0]을 2차원으로 변환
- reshape() : 차원 변환
- -1은 해당 차원의 크기를 자동으로 계산
- (1, -1) : 1차원을 자동으로 맞는차원으로 바꿔줌
X_test[0], y_test[:1]
X_test[:1], X_test[0].reshape(1, -1)
# 1번 방법(2차원으로 변환)
y_pred_0 = model.predict(X_test[:1])
# 2번 방법(2차원으로 변환)
# y_pred_0 = model.predict(X_test[0].reshape(1, -1))
y_pred_0, y_test[:1]
(array([[37346.76]], dtype=float32),
521 37736.352245
Name: 주택_가격, dtype: float64)
'인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝DL] 순환신경망(RNN) - 장기기억 순환신경망(LSTM), 게이트웨이 반복 순환신경망(GRU) (3) | 2024.01.08 |
|---|---|
| [딥러닝DL] DNN 분류데이터사용 (1) | 2024.01.05 |
| [딥러닝DL] 심층신경망 훈련 및 성능향상2 - 성능규제(Dropout), 모델 저장 및 불러오기, 콜백함수(ModelCheckpoint, EarlyStopping) (1) | 2024.01.05 |
| [딥러닝DL] 심층신경망(DNN) 훈련 및 성능향상 - verbose, epoch, history, 시각화 (2) | 2024.01.03 |
| [딥러닝] 신경망계층 추가방법 및 성능향상방법 - 옵티마이저 (1) | 2024.01.03 |




