YOLO ✨
YOLO(You Only Look Once)
- "욜로"라고 칭합니다.
- 한개의 네트워크(계층, 모델 같은 의미로 칭함)에서 객체(물체, 사물)을 탐지
- 탐지된 객체의 영역(바운딩 박스 - 사각형)과 객체의 이름(사람, 고양이...)을 표시해 주는 기능을 수행함
- 객체 탐지 기술이라고 해서 "Object Detection" 이라고 언어 소통이 됩니다.
- 객체탐지는 컴퓨터 비전 기술의 세부 분야 중 하나로 주어진 이미지 또는 영상 내에 사용자가 관심있는 객체를 탐지하는 기술을 의미함
- 객체탐지 모델을 만들기에 앞서 → 바운딩 박스를 만드는 것이 우선시 되어야 함
* 바운딩 박스란?
→ 사각형의 시작 좌표(x1, y1), 종료 좌표(x2, y2)로 표현되는 타겟 위치(객체 위치)를
사각형으로 표현한 것을 의미함
YOLO 원리✨
YOLO(You Only Look Once) 원리
- 이미지를 입력으로 받음(이미지 파일 또는 카메라에서 들어오는 영상)
- 이미지 파일, 영상 파일 등을 이용해서 numpy의 배열(array)로 데이터 생성이 가능하다면, 처리가능
- 이미지 내부를 격자(그리드)로 세분화해서 예측하는 구조를 가짐
- 예측된 부분은 바운딩 박스로 그려줌
- 이미 훈련된 모델을 사용할 수 있기 때문에, 별도의 훈련모델을 생성하지 않아도 됨
(경우에 따라, 별도의 객체 인지를 위해 재훈련하여 사용하는 경우도 있음)
YOLO 사용법✨
YOLO(You Only Look Once) 사용법
- YOLO를 사용하기 위해서는 YOLO기반의 딥러닝 프레임워크가 필요함
- YOLO 기반의 딥러닝 프레임워크 종류
- DarkNet, DarkFlow, OpenCV
DarkNet 프레임워크
- YOLO 개발자가 만든 프레임워크
- 장점 : 객체 탐지 속도가 빠름, GPU 또는 CPU와 함께 사용가능
- 단점 : 리눅스 운영체제(OS)에서 안정적으로 작동됨
: GPU와 CPU 동시 사용 시에 속도가 빠름
DarkFlow 프레임워크
- DarkNet 프레임워크를 TensorFlow에 적용한 것
- 장점 : 객체 탐지 속도가 빠름, GPU 또는 CPU와 함께 사용가능
: 리눅스, 윈도우, 맥과 호환가능
- 단점 : 설치가 매우 복잡함
OpenCV 프레임워크
- 주로 사전 개발 테스트 시에 많이 사용되는 프레임워크
- 장점 : 설치가 간단하며, 리눅스, 윈도우, 맥과 호환가능
- 단점 : CPU에서만 작동함
: 실시간 영상 처리시에 속도가 다소 느릴수 있음
YOLO 모델 및 환경파일 다운로드 및 설정 ✨
0. 파일관리 폴더 생성
- yolo/config/
1. YOLO 가중치(weights) 파일 다운로드 받기
- https://pjreddie.com/media/files/yolov3.weights
- https://pjreddie.com/media/files/yolov2-tiny.weights
- config 폴더 안에 다운받은 2개 파일 위치 시키기
2. YOLO 환경설정 파일 다운받기
- https://github.com/pjreddie/darknet
- 접속 후 [다운로드] : 초록색 <>code 화살표 누른 후 DownloadZIP 클릭 접속 후
darknet-master.zip[다운로드] → 압축풀기
- cfg 폴더 안에 → "yolov3.cfg", "yolov2-tiny.cfg" 2개 파일을 config 폴더 안에 위치 시키기
- data 폴더 안에 → "coco.names" 1개 파일을 config 폴더 안에 위치 시키기
- "coco.names" 파일 → 메모장으로 열어보기 [라벨링 데이터 - 객체인지된]
- "yolov3.cfg" 파일 → 메모장으로 열어보기 [모델 환경설정 파일]
- cardataset 폴더 → "train_solution_bounding_boxes (1).csv"
→ 메모장으로 열어보기 [이미지당 자동차 위치좌표값 image,xmin,ymin,xmax,ymax]
3. 테스트 데이터 다운로드 하기(자동차 데이터셋 사용)
- https://www.kaggle.com/sshikamaru/car-object-detection
- 오른쪽 상단 [다운로드] 클릭 → 다운로드(archive.zip) → 압축풀기(data폴더)
- data 폴더 이름을 cardataset으로 변경 후
- yolo/ 폴더 밑으로 위치하기
4. OpenCV 프레임워크 설치하기
- 가상환경 활성화 → pip install opencv-python
YOLO 실행 - 샘플 1개만✨
사용할 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
"""OpenCV 프레임워크 라이브러리"""
import cv2
자동차 데이터셋에서 바운딩 박스 정보 읽어들이기
"""자동차 이미지별 → 바운딩박스 정보 데이터 읽어들이기
- 변수명 : box
- 사용데이터파일 : train_solution_bounding_boxes (1).csv
"""
box = pd.read_csv("./yolo/cardataset/train_solution_bounding_boxes (1).csv")
box
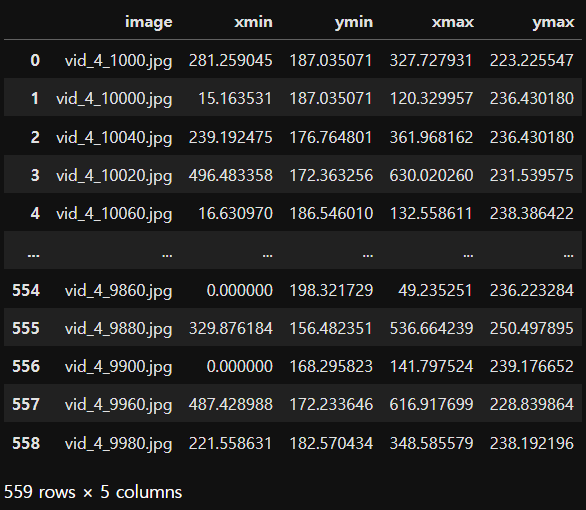
⭐결측치 확인⭐
- 절대 결측치가 있으면 안됨 !! (img외에 object가 있으면 안됨 전부 숫자값이여야 함)
box.info()

자동차 이미지에 바운딩박스 표시하기(Object Detection)
[샘플 자동차 이미지 1개 가지고 오기]
- imread() : 이미지 파일을 읽어들이는 함수
- 반환값은 이미지 데이터(3차원 이미지 픽셀 데이터)
- 높이, 너비, 채널 (흑백은 0, 컬러는 3(RGB 또는 BGR))
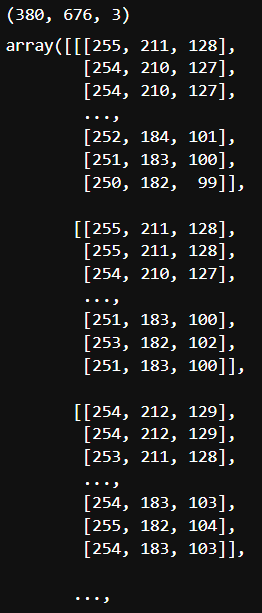
sample1 = cv2.imread("./yolo/cardataset/training_images/vid_4_1000.jpg")
print(sample1.shape)
sample1
색상 채널 순서 정의하기
- Yolo에서는 현재 색상순서를 RGB를 사용함
- 저장된 이미지 데이터의 순서는 BGR를 사용하고 있음(옛날 이미지)
- 색상순서를 RGB로 바꾸는 작업이 필요함
- cvtColor() : 색상 순서 바꾸는 함수
- COLOR_BGR2RGB : BGR → RGB
sample = cv2.cvtColor(sample1, cv2.COLOR_BGR2RGB)
sample

사용하는 이미지 파일이름에 해당하는 바운딩박스의 xy 좌표값 추출하기
- vid_4_1000.jpg 이미지 파일이름은 0번째 인덱스에 있음
- 0번째 인덱스의 모든 컬럼값 추출하기
point = box.iloc[0]
point, type(point)

시작 좌표(xmin, ymin)와 종료 좌표(xmax, ymax) 추출하기
- 시작 좌표 변수 : pt1 = (xmin, ymin)
- 종료 좌표 변수 : pt2 = (xmax, ymax)
- 시작과 종료 좌표는 "튜플 타입"으로 생성
- 각 포인트 값은 "정수 타입"으로 변환
pt1 = (int(point.xmin), int(point.ymin))
pt2 = (int(point.xmax), int(point.ymax))
### 강사님
# pt1 = (point["xmin"], point["ymin"])
# pt2 = (point["xmax"], point["ymax"])
pt1, pt2
((281.2590449, 187.0350708), (327.7279305, 223.225547))
▼
((281, 187), (327, 223))
이미지 보이기
이미지 픽셀 데이터를 이미지로 보이기
- 이때 이미지 픽셀 데이터의 차원은? => 3차원
plt.imshow(sample)

자동차 좌표값을 이용해서 이미지에 바운딩 박스 그리기
* rectangle() : 사각형(바운딩박스는 사각형으로 표시하기 위해)을 그리는 함수
- sample : 원본 이미지 데이터
- pt1 : 박스의 시작점 좌표
- pt2 : 박스의 종료 좌표
- color : 박스 선의 색상 지정
color=(255, 0, 0) : 빨간색(rgb)
- thickness : 박스 선의 굵기 지정
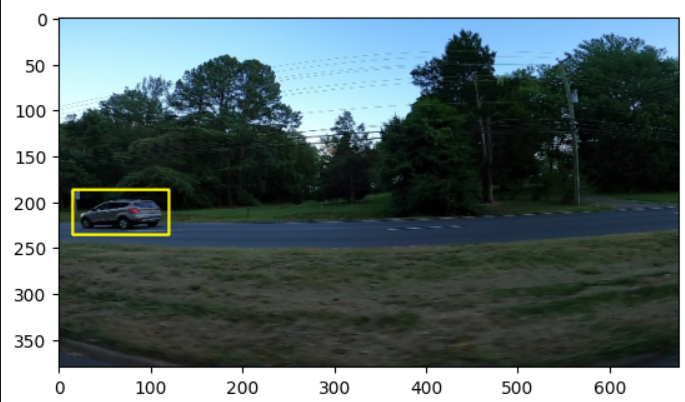
cv2.rectangle(sample, pt1, pt2, color=(255, 0, 0), thickness=2)
"""이미지에 바운딩박스를 그리고 잘 보이는지 다시 imshow() 하기"""
plt.imshow(sample)

YOLO 실습해보기 ✨
이미지 파일(vid_4_10000.jpg)에 대한 바운딩 박스도 그려보기
"""이미지 불러오기"""
sample2 = cv2.imread("./yolo/cardataset/training_images/vid_4_10000.jpg")
"""RGB 순서로 변경하기"""
sample2_rgb = cv2.cvtColor(sample2, cv2.COLOR_BGR2RGB)
"""해당 이미지 파일에 대한 좌표값 추출하기"""
# point2 = box[box["image"]=="vid_4_10000.jpg"]
point2 = box.iloc[1]
"""시작좌표와 종료좌표 생성하기"""
pt1_2 = (int(point2.xmin), int(point2.ymin))
pt2_2 = (int(point2.xmax), int(point2.ymax))
"""원본 이미지에 바운딩박스 그리기"""
cv2.rectangle(sample2_rgb, pt1_2, pt2_2, color=(255, 250, 0), thickness=2)
"""이미지에 바운딩 박스를 그리고 잘 보이는지 다시 imshow()하기"""
plt.imshow(sample2_rgb)
YOLO에서 제공된 가중치 모델을 이용해서 객체(자동차) Detection하기 ✨
[사용되는 파일]
- yolov3.weights : 이미 훈련된 모델의 가중치 데이터 파일
- yolov3.cfg : yolo 모델 매개변수 설정 파일
- coco.names : 인식(감지)된 객체의 레이블 명칭(이름)이 저장된 파일
가중치 데이터 및 환경설정 파일 읽어들이기
- YOLO는 DNN(심층신경망) 모델을 사용
- readNet() : OpenCV에서 딥러닝 모델을 읽어오는 함수
net = cv2.dnn.readNet("./yolo/config/yolov3.weights", "./yolo/config/yolov3.cfg")
net
< cv2.dnn.Net 000001CE489250B0>
레이블 명칭(이름) 데이터 읽어들이기
- 인식한 객체에 대한 이름을 표시하기 위해서
- with문 : 메모리를 사용하고 바로 반환시킴 (많이 씀)
- open() : 파일 열기
→ 모드 : r 읽기모드, w 쓰기모드, b 바이너리
- strip() : 왼쪽 오른쪽 공백제거
- readlines() : 파일 내에 문장들을 행단위로 모두 읽어들이기
"""저장할 변수 정의"""
classes = []
with open("./yolo/config/coco.names", "r") as f :
classes = [line.strip() for line in f.readlines()]
classes

YOLO가 사용하는 계층 구조 확인하기
- getLayerNames() : 훈련에 사용한 계층 확인하는 함수
- 우리가 사용했던 model.summary()함수의 기능과 유사
layer_names = net.getLayerNames()
layer_names

YOLO에서 사용하는 출력 계층 확인하기
- YOLO는 객체 검출을 위해서 여러 개의 출력 계층을 사용하고 있음
- 객체 탐지 시에 출력계층에서 출력해준 값들을 이용해서 사용
→ 바운딩 박스의 좌표값, 객체 인지 정확도, 인지된 객체의 레이블 명칭(이름) 등의 출력을 담당함
* net.getUnconnectedOutLayers()
: 다음 계층과 연결되지 않은(UnConnect) 마지막 계층(OutLayer)을 추출하는 함수
: 출력계층 추출함수로, 출력계층의 인덱스 위치를 반환해줌
- layer_names[i-1] : -1을 하는 이유는? 반환값의 인덱스 순서는 1부터 시작된 인덱스 값, 따라서 1을 빼주면 됨
⭐[layer_names[ i-1] for i in net.getUnconnectedOutLayers()] ⭐
output_layer = [layer_names[ i-1] for i in net.getUnconnectedOutLayers()]
"""출력계층 추출함수로, 출력계층의 인덱스 위치를 반환해줌"""
print(net.getUnconnectedOutLayers())
output_layer
[200 227 254]
['yolo_82', 'yolo_94', 'yolo_106']
샘플 이미지 데이터 가져오기
img = cv2.imread("./yolo/cardataset/training_images/vid_4_10000.jpg")
img

BGR을 RGB로 변환하기
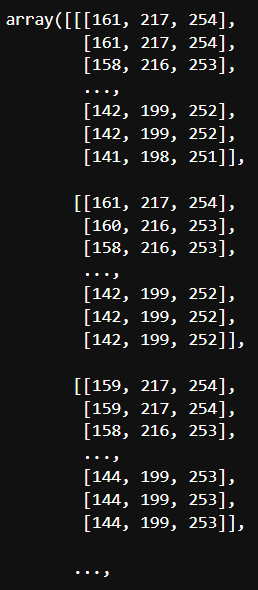
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img
높이와 너비 추출
- 바운딩박스의 시작좌표와 종료좌표값을 계산할 때 사용할 실제 높이와 너비 추출
- yolo 출력계층에서 예측한 좌표값은 객체의 중심점 좌표에 대한 비율값을 추출함
- 비율에 실제 높이와 너비를 이용해서 예측된 중심점 좌표를 계산하여
바운딩 박스의 시작좌표와 종료좌표를 정의해야됨
height, width, channels = img.shape
height, width, channels
(380, 676, 3)
Blob(Binary Large Object)✨
Blob(Binary Large Object)
- Blob는 이미지 처리 및 딥러닝에서 사용되는 데이터 구조임
- 이미지나 동영상에서 추출된 특정 부분이나 물체를 나타내기 위한 데이터 구조 형태로 되어 있음
- 주로 딥러닝 모델에 이미지를 전달하거나
이미지 프로세싱 작업에서 특정 부분을 추출하여 처리하는데 사용되는 구조임
(객체 탐지용 데이터 구조라고 이해하면 됩니다.)
- YOLO 모델에서 사용되는 데이터 구조가 Blob 구조를 따름
→ 사용할 이미지를 Blob 데이터 구조로 변환한 후에
→ Yolo 네트워크(모델)에 전달하여 객체를 검출하게 됨
- Blob 데이터 구조에 포함될(된) 수 있는 값들
→ 이미지 데이터 : 이미지 또는 영상 프레임(이미지)에서 추출된 특정 영역에 대한 이미지 데이터
→ 채널 정보 : 컬러 이미지인 경우 RGB 또는 BGR과 같은 컬러 정보
→ 공간 차원 정보 : 높이와 너비
→ 픽셀 값 범위 : 0~255까지의 값을 갖는 흑백 이미지 데이터 또는 -1~1 or 0~1 사이의 정규화된 이미지 값
- Yolo 모델(네트워크)에서는 이미지 데이터를 바로 사용할 수 없음
→ 먼저 이미지를 Blob 데이터 형태로 변환해야함
→ Blob 데이터를 통해 Yolo가 예측할 수 있도록 이미지에서 특징을 찾아내고,
크기를 저장하는 작업을 수행합니다.
→ 이미지 크기 저장을 이미지 크기 정규화라고 합니다.
▶ 이미지 크기 정규화 : 사용되는 높이와 너비의 이미지 사이즈를 통일 시키는 작업
- Yolo에서 사용되는 이미지 크기
→ 320 x 320 : 이미지가 작고, 정확도는 떨어지지만 속도가 빠름
→ 609 x 609 : 이미지가 크고, 정확도는 높지만 속도가 느림
→ 416 x 416 : 이미지 중간크기, 정확도와 속도가 적당함(주로 사용되는 크기임)
YOLO모델이 이미지 데이터를 처리하기 위한 Blob 형태의 데이터로 구조화하기 ✨
원본 이미지 데이터를 Blob로 변환하면서, 동시에 정규화(사이즈 통일)하기
cv2.dnn.blobFromImage()
- 사용 함수 : cv2.dnn.blobFromImage()
- 4차원으로 반환됨
- img : 원본 이미지 데이터
- 1/256 : 픽셀값에서 256으로 나누어서 데이터 정규화 진행
: 0~1 사이의 값으로 정규화
- (416, 416) : 높이와 너비의 사이즈를 통일시키는 정규화 진행
- (0, 0, 0) : 원본 이미지의 채널 값을 흑백 색으로 변환하기
- swapRB : RGB에서 R값과 B값을 바꿀 것인지 결정(기본값 False)
: True인 경우 BGR을 RGB로 변경
- crop : 크기를 조정한 후에 이미지를 자를지 여부 결정
: 일반적으로 자르면 안되기에 False 지정(기본값 False)
: 크기가 변경된 사이즈로 이미지를 변환해서 사용할지, 아니면 변경 사이즈 부분을 제외하고 자를지 결정
blob = cv2.dnn.blobFromImage(
img,
1/256,
(416, 416),
(0, 0, 0),
swapRB = True,
crop = False
)
blob.shape
(1, 3, 416, 416)
Yolo 모델에 데이터 넣어주기 (입력계층에 들어가게 됨)
"""Yolo 모델에 입력 데이터로 넣어주기"""
net.setInput(blob)
Yolo 모델의 출력계층을 이용해서 결과 받아오기
"""Yolo 모델의 출력계층"""
output_layer
['yolo_82', 'yolo_94', 'yolo_106']
⭐ 입력데이터를 이용해서 예측된 출력결과 받아오기
- net.forward() : Yolo 모델이 이미지 내에 있는 객체를 인식하여 정보를 출력해줍니다.
이때, 출력계층의 이름을 넣어서, 해당 출력계층의 값이 반환되게 됩니다.
⭐ array 배열의 3개 데이터를 튜플형태로 반환함
- 각 튜플은 출력계층 3개가 출력해준 값들임
outs = net.forward(output_layer)
outs
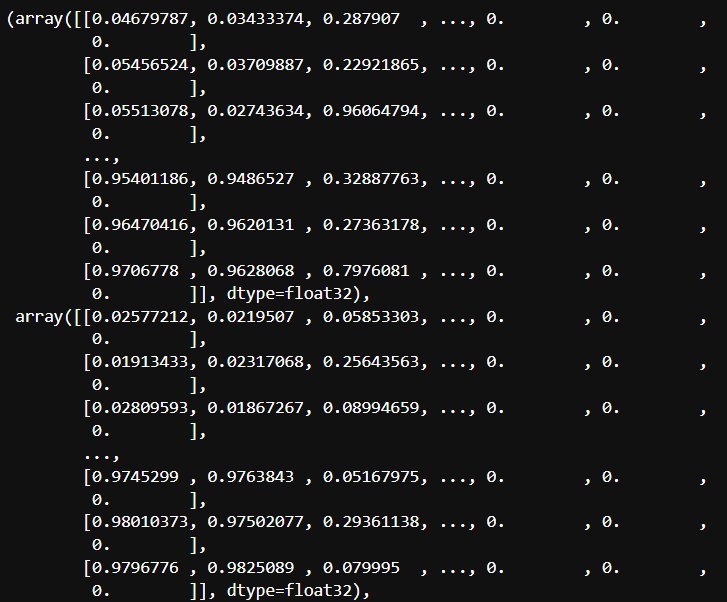
"""Yolo가 인지한 데이터 1개"""
outs[0][0]

인식된 객체(물체) 좌표, 레이블 명칭(이름), 정확도 확인하기 ✨
"""인식된 객체(물체)의 인덱스 번호를 담을 변수"""
class_ids = []
"""인식된 객체의 인식률(정확도)를 담을 변수"""
confidences = []
"""인식된 객체의 좌표값을 담을 변수"""
boxes = []
"""출력계층이 반환한 값들을 처리하기 위하여 반복문 사용"""
for out in outs :
print(out)

⭐ detection 설명
- 0번 인덱스 값 : 인식된 객체(바운딩박스)의 x 중심좌표
- 1번 인덱스 값 : 인식된 객체(바운딩박스)의 y 중심좌표
- 2번 인덱스 값 : 바운딩 박스의 너비
- 3번 인덱스 값 : 바운딩 박스의 높이
- 4번 인덱스 값 : 물체 인식률
- 5번 인덱스부터 전체 : 바운딩 박스에 대한 클래스(레이블 명칭(이름)) 확률 값들
→ 5번 이후의 갯수는 레이블의 갯수(클래스 수) 만큼
→ 레이블 이름은 실제 레이블 값들과 비교하여 가장 높은 값을 가지는 인덱스의 값을 이용하여 실제 레이블 이름 추출함
"""출력계층이 반환한 값들을 처리하기 위하여 반복문 사용"""
for out in outs :
# print(out)
"""인식된 객체에 대한 정보가 담겨 있음"""
for detection in out :
print(detection)

"""출력계층이 반환한 값들을 처리하기 위하여 반복문 사용"""
for out in outs :
# print(out)
"""인식된 객체에 대한 정보가 담겨 있음"""
for detection in out :
# print(detection)
"""인식된 객체에 대한 정보 추출하기(클래스 = 레이어 명칭) 확률 정보"""
scores = detection[5:]
# print(len(scores), scores)
"""scores값이 가장 큰 인덱스 번호 찾기
- 0은 인식 못했다는 의미
- 가장 큰 인덱스 값 : 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
"""
class_id = np.argmax(scores)
# print(class_id)
"""score 값이 가장 큰 위치의 인덱스 번호에 해당하는 값은 인식률(정확도)를 의미"""
confidence = scores[class_id]
print(confidence)
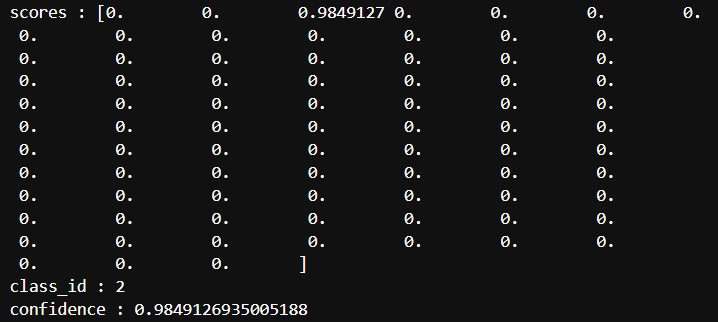
"""정확도 50% 이상인 데이터에 대해서 처리하기"""
if confidence > 0.5 :
print(f"scores : {scores}")
print(f"class_id : {class_id}")
print(f"confidence : {confidence}")

"""출력계층이 반환한 값들을 처리하기 위하여 반복문 사용"""
for out in outs :
# print(out)
"""인식된 객체에 대한 정보가 담겨 있음"""
for detection in out :
# print(detection)
"""인식된 객체에 대한 정보 추출하기(클래스 = 레이어 명칭) 확률 정보"""
scores = detection[5:]
# print(len(scores), scores)
"""scores값이 가장 큰 인덱스 번호 찾기
- 0은 인식 못했다는 의미
- 가장 큰 인덱스 값 : 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
"""
class_id = np.argmax(scores)
# print(class_id)
"""score 값이 가장 큰 위치의 인덱스 번호에 해당하는 값은 인식률(정확도)를 의미"""
confidence = scores[class_id]
print(confidence)
"""정확도 50% 이상인 데이터에 대해서 처리하기"""
if confidence > 0.5 :
# print(f"scores : {scores}")
# print(f"class_id : {class_id}")
# print(f"confidence : {confidence}")
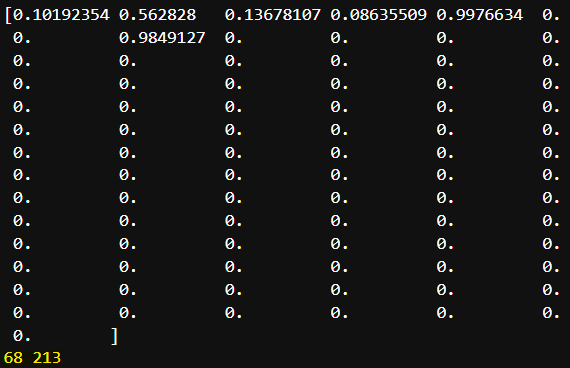
"""바운딩 박스의 상태적 x, y 좌표 추출하여
- 실제 길이 좌표(절대 좌표)로 변환하기"""
print(detection)
"""실제 중심점 x 좌표"""
center_x = int(detection[0]*width)
"""실제 중심점 y 좌표"""
center_y = int(detection[1]*height)
print(center_x, center_y)

"""출력계층이 반환한 값들을 처리하기 위하여 반복문 사용"""
for out in outs :
# print(out)
"""인식된 객체에 대한 정보가 담겨 있음"""
for detection in out :
# print(detection)
"""인식된 객체에 대한 정보 추출하기(클래스 = 레이어 명칭) 확률 정보"""
scores = detection[5:]
# print(len(scores), scores)
"""scores값이 가장 큰 인덱스 번호 찾기
- 0은 인식 못했다는 의미
- 가장 큰 인덱스 값 : 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
"""
class_id = np.argmax(scores)
# print(class_id)
"""score 값이 가장 큰 위치의 인덱스 번호에 해당하는 값은 인식률(정확도)를 의미"""
confidence = scores[class_id]
print(confidence)
"""정확도 50% 이상인 데이터에 대해서 처리하기"""
if confidence > 0.5 :
# print(f"scores : {scores}")
# print(f"class_id : {class_id}")
# print(f"confidence : {confidence}")
"""바운딩 박스의 상태적 x, y 좌표 추출하여
- 실제 길이 좌표(절대 좌표)로 변환하기"""
print(detection)
"""실제 중심점 x 좌표"""
center_x = int(detection[0]*width)
"""실제 중심점 y 좌표"""
center_y = int(detection[1]*height)
print(center_x, center_y)
"""바운딩 박스의 상대적 너비와 높이 비율 추출하기"""
""" - 실제 너비로 변환"""
w = int(detection[2]*width)
""" - 실제 높이로 변환"""
h = int(detection[3]*height)
print(w, h)
"""시작점 좌표 계산하기"""
x = int(center_x - w / 2 )
y = int(center_y - h / 2 )
print(x, y)
"""이미지 좌표계
- 좌상단이 0, 0 입니다.
- 그래프 좌표계는 좌하단이 0, 0 입니다.
"""
"""실제 x, y, 너비, 높이 값을 리스트로 담기"""
boxes.append([x, y, w, h])
"""객체 인식률(정확도) 담기"""
confidences.append(float(confidence))
"""레이블 명칭(이름) 인덱스 담기"""
class_ids.append(class_id)
print(boxes)
print(confidences)
print(class_ids)
68 213
92 32
22 197
[[22, 197, 92, 32]]
[0.9849126935005188]
[2]
중복된 바운딩 박스 제거하기
- 인식된 객체별로 → 1개의 바운딩 박스만 남기기
- cv2.dnn.NMSBoxes() : 중복 바운딩 박스 제거하는 함수
- boxes : 추출된 바운딩 박스 데이터
- confidences : 바운딩 박스별 정확도
- 0.5 : 정확도에 대한 임계값, 바운딩 박스 정확도가 0.5보다 작으면 박스 제거
- 0.4 : 비최대 억제 임계값(IoU), 0.4보다 크면 박스 제거
: 0.4보다 큰 IoU를 가진 박스들 중에서 가장 높은 정확도를 가진 박스를 선택하고, 나머지는 제거
- NMSBoxes() 함수가 반환하는 값은 제거된 후 남은 바운딩 인덱스의 번호값 리스트
indexes
array([0])
원본 이미지에 예측한 위치에 바운딩 박스와 레이블(이름), 정확도 출력하기 ✨
[ 바운딩 박스의 색상 지정하기 ]
- 인식된 객체가 많은 경우, 각각 색상을 지정해서 구분해 줄 필요성이 있기 때문에
→ 랜덤하게 색상을 추출하여 정의
- np.random.uniform() : 랜덤한 값 추출 함수
- 색상 RGB의 형태로 추출하기 위해 값의 범위는 0~255를 사용
- 0, 255 : RGB 각 값의 랜덤 범위
- size = (len(boxes), 3) : 추출할 사이즈 : 행, 열 정의
→ 인식된 각 바운딩 박스의 갯수만큼, 3개씩의 RGB값 추출을 의미함
[ 인식된 객체의 레이블 명칭(이름)과 정확도 넣기(그리기) ]
* putText() : 원본 이미지에 텍스트 넣는 함수
- img : 원본 이미지
- label : 인식된 레이블 명칭(이름)
- confidence : 인식률(정확도)
- (x, y+20) : 텍스트 시작 좌표
- font : 폰트 스타일
- font 다음의 숫자 2 : 폰트 사이즈
- (0, 255, 0) : 폰트 색상
- 마지막 숫자 2 : 폰트 굵기
"""<폰트 스타일 지정>"""
font = cv2.FONT_HERSHEY_PLAIN
"""<바운딩 박스의 색상 지정하기>"""
colors = np.random.uniform(0, 255, size=(len(boxes), 3))
### 인식된 객체가 있는 경우
if len(indexes) > 0:
"""무조건 1차원으로 변환"""
print(indexes.flatten())
for i in indexes.flatten() :
"""x, y, w, h 값 추출하기"""
x, y, w, h = boxes[i]
print(x, y, w, h)
"""실제 레이블 명칭(이름) 추출하기"""
label = classes[class_ids[i]]
print(label)
"""인식률(정확도) 추출하기 - 문자열 타입으로 변환해줘야함!!!"""
confidence = str(round(confidences[i], 2))
print(confidence)
"""바운딩 박스의 색상 추출하기"""
color = colors[i]
print(color)
"""바운딩 박스 그리기
- 마지막 값 2 : 바운딩 박스 선의 굵기(thickness)
"""
cv2.rectangle(img, (x, y), ((x+w),(y+h)), color, 2)
"""인식된 객체의 레이블 명칭(이름)과 정확도 넣기(그리기)"""
cv2.putText(img, label + " " + confidence,
(x, y-20), font, 2, (0, 255, 0), 2)
plt.imshow(img)
### 인식된 객체가 없는 경우
else :
print("인식된 객체가 없습니다!!!")

한번 실행하면 이미지에 텍스트가 입혀지므로 한번만 실행하도록!
Yolo 모델로 위에서 처리한 부분을 함수로 정의하기 ✨
- 함수 이름 : predict_yolo(img_path)
def predict_yolo(img_path) :
"""이미지 데이터 가져오기"""
img = cv2.imread(img_path)
"""BGR을 RGB로 변환하기"""
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
height, width, channels = img.shape
blob = cv2.dnn.blobFromImage(
img,
1/256,
(416, 416),
(0, 0, 0),
swapRB = True,
crop = False
)
"""Yolo 모델에 입력 데이터로 넣어주기"""
net.setInput(blob)
outs = net.forward(output_layer)
### ----------------------------------------
"""인식된 객체(물체)의 인덱스 번호를 담을 변수"""
class_ids = []
"""인식된 객체의 인식률(정확도)를 담을 변수"""
confidences = []
"""인식된 객체의 좌표값을 담을 변수"""
boxes = []
"""출력계층이 반환한 값들을 처리하기 위하여 반복문 사용"""
for out in outs :
# print(out)
"""인식된 객체에 대한 정보가 담겨 있음"""
for detection in out :
# print(detection)
"""인식된 객체에 대한 정보 추출하기(클래스=레이어 명칭) 확률 정보"""
scores = detection[5:]
# print(len(scores), scores)
"""scores값이 가장 큰 인덱스 번호 찾기
- 0은 인식 못했다는 의미
- 가장 큰 인덱스 값 : 레이블 명칭(이름)이 있는 리스트 배열의 인덱스 값을 의미함
"""
class_id = np.argmax(scores)
### print(class_id)
"""score 값이 가장 큰 위치의 인덱스 번호에 해당하는 값은 인식률(정확도)를 의미
"""
confidence = scores[class_id]
### print(confidence)
"""정확도(인식률, 탐지율) 50% 이상인 데이터에 대해서 처리하기"""
if confidence > 0.5 :
"""바운딩 박스의 상태적 중심 x, y 좌표 비율 추출하여
- 실제 중심점 길이 좌표(절대 좌표)로 변환하기
"""
"""실제 중심점 x 좌표"""
center_x = int(detection[0] * width)
"""실제 중심점 y 좌표"""
center_y = int(detection[1] * height)
# print(center_x, center_y)
"""바운딩 박스의 상대적 너비와 높이 비율 추출하기"""
""" - 실제 너비로 변환"""
w = int(detection[2] * width)
""" - 실제 높이로 변환"""
h = int(detection[3] * height)
# print(w, h)
"""시작점 좌표 계산하기"""
x = int(center_x - w / 2)
y = int(center_y - h / 2)
# print(x, y)
"""이미지 좌표계
- 좌상단이 0, 0 입니다.
- 그래프 좌표계는 좌하단이 0, 0
"""
"""실제 x, y, 너비, 높이 값을 리스트로 담기"""
boxes.append([x, y, w, h])
"""객체 인식률(정확도) 실수형 타입으로 담기"""
confidences.append(float(confidence))
"""레이블 명칭(이름) 인덱스 담기"""
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
### -------------------------------------------------
"""<폰트 스타일 지정>"""
font = cv2.FONT_HERSHEY_PLAIN
"""<바운딩 박스의 색상 지정하기>"""
colors = np.random.uniform(0, 255, size=(len(boxes), 3))
"""인식된 객체가 있는 경우"""
if len(indexes) > 0 :
"""무조건 1차원으로 변환"""
# print(indexes.flatten())
for i in indexes.flatten() :
"""x, y, w, h 값 추출하기"""
x, y, w, h = boxes[i]
# print(x, y, w, h)
"""실제 레이블 명칭(이름) 추출하기"""
label = str(classes[class_ids[i]])
# print(label)
"""인식률(정확도) 추출하기"""
confidence = str(round(confidences[i], 2))
# print(confidence)
"""바운딩 박스의 색상 추출하기"""
color = colors[i]
# print(color)
"""바운딩 박스 그리기
- 마지막 값 2 : 바운딩 박스 선의 굵기
"""
cv2.rectangle(img, (x, y), ((x+w), (y+h)), color, 2)
""" 인식된 객체의 레이블 명칭(이름)과 정확도 넣기(그리기)"""
cv2.putText(img, label + " " + confidence,
(x, y+20), font, 2, (0, 255, 0), 2)
plt.imshow(img)
### 인식된 객체가 없는 경우
else :
print("인식된 객체가 없습니다!!!")
테스트 이미지 모두 가지고 오기
import glob
import random
paths = glob.glob("./yolo/cardataset/testing_images/*.jpg")
"""랜덤하게 이미지 한개 선택하기"""
img_path = random.choice(path)
img_path
###'./yolo/cardataset/testing_images\\vid_5_27420.jpg'
"""파일 경로의 문자열 내에 역슬래시를 정상적인 슬래시로 바꾸기"""
img_path = img_path.replace("\\", "/")
img_path
"""함수 호출하기"""
print(f"인식에 사용된 이미지 파일명 : {img_path}")
predict_yolo(img_path)

임의 이미지로 테스트 해보기 ✨
- 함수 이름 : predict_yolo(img_path)
img_paths = glob.glob("./yolo/carimg.jpg")
img_path = img_paths[0]
"""함수 호출하기"""
print(f"인식에 사용된 이미지 파일명 : {img_path}")
predict_yolo(img_path)

- 이미지 폴더 경로 : "C:\Users\user\oooo\09_딥러닝\08_YOLO_객체탐지_네트워크(모델)\yolo\img\blackcat.jpg"
"""테스트 이미지 모두 가지고 오기"""
import glob
import random
paths = glob.glob("./yolo/img/*.jpg")
"""랜덤하게 이미지 한개 선택하기"""
img_path = random.choice(paths)
###'./yolo/cardataset/testing_images\\vid_5_27420.jpg'
"""파일 경로의 문자열 내에 역슬래시를 정상적인 슬래시로 바꾸기"""
img_path = img_path.replace("\\", "/")
"""함수 호출하기"""
print(f"인식에 사용된 이미지 파일명 : {img_path}")
predict_yolo(img_path)

'인공지능 > 딥러닝' 카테고리의 다른 글
| [YOLO] 이미지 증식 테스트 + 사람이미지 증식 및 4차원 독립변수와 종속변수(라벨링) 생성하기 + (응용)비프음 출력 (41) | 2024.01.11 |
|---|---|
| [YOLO] YOLO 카메라 객체탐지 (2) | 2024.01.11 |
| [머신러닝 + 딥러닝] 에너지 사용 패턴 확인을 통한 부하 타입 분류 실습해보기 (0) | 2024.01.10 |
| [딥러닝DL]합성곱신경망(CNN)을 이용한 이미지 분류 (1) | 2024.01.08 |
| [딥러닝DL] RNN응용 규칙기반 챗봇 (0) | 2024.01.08 |




