앙상블 모델
- tree구조(결정트리)를 기반으로 만들어진 모델
- 여러개의 트리 모델을 이용해서 훈련하는 모델을 앙상블 모델이라고 칭합니다.
앙상블 모델 분류
- 회귀와 분류에서 모두 사용한 모델들 입니다.
- sklearn 패키지 모델은 모두 가능.
- xgb도 가능.
분류 모델
- 랜덤포레스트
- 엑스트라트리
- 그레디언트 부스팅
- 히스트그레디언트부스팅
- XGboost
앙상블 모델 - 배깅(Bagging)과 부스팅(Boosting) 방식
- 앙상블 모델은 여러개의 트리를 사용하기 때문에
→ 훈련 데이터를 여러 모델(여러 트리)에 적용하는 방식에 따라서
→ 배깅과 부스팅 방식으로 구분합니다.
배깅(Bagging) 방식
- 사용되는 여러개의 모델(여러 트리)들은 서로 독립적으로 사용됨(연관성 없음)
- 훈련 데이터는 여러 모델에 랜덤하게 적용되며, 중복되는 데이터가 있을 수도 있음.
- 훈련데이터를 사용 후에는 반환하는 방식을 사용함.
→ 반환 후에 다시 랜덤하게 추출하여 여러 모델(여러 트리)에 적용합니다.
- 대표적인 배깅 앙상블 모델은 랜덤포레스트 모델이 있음.
- 배깅 앙상블 모델 : 랜덤포레스트, 엑스트라트리
- 예측 : 회귀에서는 평균값을 이용하며, 분류에서는 과반수(확률)에 따라 결정됨.
- 과적합을 해소하는 모델로 주로 사용됨
부스팅(Boosting) 방식
- 사용되는 여러개의 모델(여러 트리)들은 서로 연관성을 가짐.
- 이전 모델(이전 트리)의 오차를 보완하여 다음 모델(다음 트리)에서 이어서 훈련이 진행되는 방식.
- 훈련데이터는 랜덤하게 추출되어 사용되지만,
→ 이전 모델 훈련에서 오차가 크게 발생했던 훈련데이터에 가중치를 부여하여 사용하게 됨.
- 대표적인 부스팅 앙상블 모델 : 그레디언트 부스팅 모델이 있음.
- 부스팅 앙상블 모델 : 그레디언트 부스팅, 히스트그레디언트부스팅, XGboost
- 정확도를 높이는 모델로 주로 사용됨.
실제 모델 적용 순서
- 분류시 최초에는 주로 랜덤포레스트 모델을 이용해서 수행합니다.
→ 정확도가 높은 모델로 유명함.(예전에… 지금은 부스트 모델이 우수한 편임.)
- 최종 모델 선정시에는 분류모델 전체 사용하여 선정.
랜덤포레스트(RandomForest)
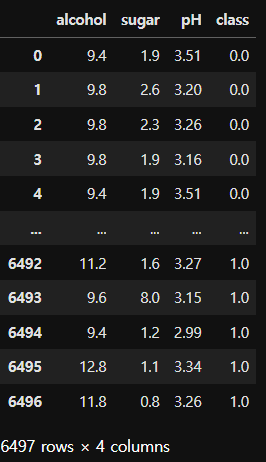
데이터 읽어드리기
wine = pd.read_csv("./data/08_wine.csv")
wine
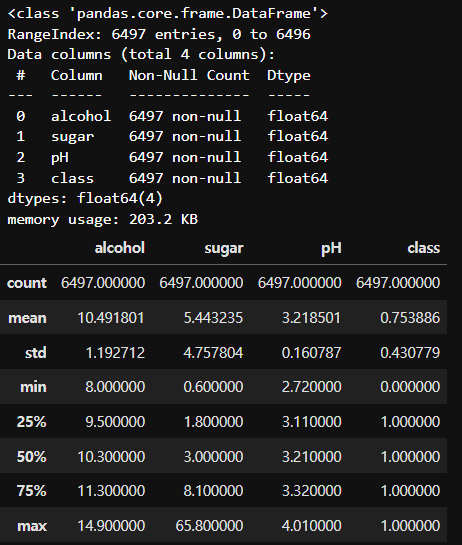
데이터 전처리
wine.info()
wine.describe()
< 와인종류 분류하기 >
- 와인종류(class): 레드와인(0), 화이트와인(1)
- 독립변수 : alchol(알콜), sugar(설탕, 당도), pH(수소이온농도; 산성 또는 염기성)
- 종속변수 : class(와인종류; 0 또는 1, 0은 레드와인, 1은 화이트와인)
독립변수와 종속변수로 데이터 분리하기
- to_numpy() : 데이터프레임(DataFrame) 객체를 NumPy 배열로 변환
- 독립변수
data = wine[["alcohol","sugar","pH"]].to_numpy()
data.shape
- 종속변수
target = wine["class"].to_numpy()
target.shape
출력 : (6497, 3)
(6497,)
정규화할지, 분류를 할지 두개의 순서는 상관없다.
정규화를 진행하고 테스트를 하거나, 테스트를 해보고 차이가 많이 났을때 정규화를 하거나
우리는 먼저 정규화를 후 테스트 진행.
현업에서는 그냥 정규화를 하고 시작한다.
(나중에 문제생기면 하루종일 바꾸느라 바쁘기때문)
훈련과 테스트데이터로 분리하기(8:2)
from sklearn.model_selection import train_test_split
- 사용변수 : train_input, train_target, test_input, test_target
train_input, test_input, train_target, test_target = train_test_split(data,
target,
test_size = 0.2,
random_state=42)
print(f"train_input={train_input.shape} / train_target={train_target.shape}")
print(f"test_input={test_input.shape} / test_target={test_target.shape}")
출력 : train_input=(5197, 3) / train_target=(5197,)
test_input=(1300, 3) / test_target=(1300,)
정규화, 표준화
<데이터 스케일링>
- 서로 다른 변수(특성)의 값을 범위(단위)를 일정한 수준으로 맞추는 작업
- 수치형 변수(특성, 퓨터, 항목, 컬럼 같은 용어)에만 적용됩니다.
- 스케일링 방법 3가지 : 아래 3가지는 구분만 될 뿐 의미는 모두 스케일링임.
→ 정규화 : StandardScaler → 분류 또는 회귀에서 사용가능하며, 주로 분류에서 사용 됨.
RobustScaler → 분류 및 회귀 모두 사용 가능.(거의사용안함, 강사님도 쓰는거 본적 없음.)
→ 표준화 : MinMaxScaler → 분류 또는 회귀에서 사용 가능, 회귀에서 주로 사용 됨.
(최대 및 최소 범위 내에서 처리되는 방식)
<라이브러리>
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import MinMaxScaler
StandardScaler - 정규화
- 훈련데이터 정규화 변수 : train_std_scaler
- 테스트데이터 정규화 변수 : test_std_scaler
ss = StandardScaler()
# fit은 무조건 훈련데이터만 해야한다. test데이터는 하지 말 것.
ss.fit(train_input)
train_std_scaler = ss.transform(train_input)
test_std_scaler = ss.transform(test_input)
print(f"{train_std_scaler.shape}/{test_std_scaler.shape}")
출력 : (5197, 3)/(1300, 3)
RobustScaler - 정규화
- 훈련데이터 정규화 변수 : train_rs_scaler
- 테스트데이터 정규화 변수 : test_rs_scaler
rs = RobustScaler()
rs.fit(train_input)
train_rs_scaler = rs.transform(train_input)
test_rs_scaler = rs.transform(test_input)
train_rs_scaler, test_rs_scaler
출력 :

MinMaxScaler - 표준화
- 훈련데이터 표준화 변수 : train_mm_scaler
- 테스트데이터 표준화 변수 : test_mm_scaler
mm = MinMaxScaler()
mm.fit(train_input)
train_mm_scaler = mm.transform(train_input)
test_mm_scaler = mm.transform(test_input)
train_mm_scaler,test_mm_scaler
출력 :
훈련하기 - StandardScaler정규화한 데이터로
[모델(클래스) 생성하기]
- cpu의 코어는 모두 사용, 랜덤값은 42 사용하여 생성하기.
- 모델 변수 이름은 rf 사용
- n_jobs=-1 사용하는 이유 빨리 쓰기위해서(연산을 빨리 해줌)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
rf
출력 :

[모델 훈련 시키기]
rf.fit(train_std_scaler, train_target)
출력 :

[훈련 및 검증(테스트) 정확도(score) 확인하기]
train_score = rf.score(train_std_scaler, train_target)
test_score = rf.score(test_std_scaler, test_target)
train_score, test_score
출력 : (0.996921300750433, 0.8892307692307693)
⭐ 해석⭐
- 가장 일반화된 모델을 나타내는 스케일링 방법으로는 StandardScaled 정규화 방법을 사용했을 때로,
- 3개 모두 0.1 이상의 과대적합의 양상을 보임
- 따라서, 하이퍼파라메터 튜닝 및 다른 분류모델에 의한 훈련이 필요할 것으로 보임
예측하기
- 예측하기는 테스트 데이터로!!!
y_pred = rf.predict(test_std_scaler)
y_pred
출력 : array([1., 0., 1., ..., 1., 1., 1.])
print(y_pred[:10])
print(test_target[:10])
출력 : [1. 0. 1. 1. 1. 1. 1. 1. 0. 1.]
[1. 0. 1. 1. 1. 0. 1. 1. 0. 1.]
성능 평가하기
<분류 모델 평가 방법>
- 정확도, 정밀도, 재현율, F1-score 값을 이용해서 평가함
- 예측에 오류가 있는지 확인 : 오차행렬도(혼동행렬도)를 통해 확인
<평가 기준>
- 정확도를 이용하여 과적합 여부 확인.
- 재현율이 높고, F1-Score 값이 높은 값을 가지는 모델을 선정하게됨 (모델 선정하는 단계에서)
- 정확도, 정밀도, 재현율, F1-Score의 모든 값은 0~1 사이의 값을 가지며, 값이 높을 수록 좋다.
시각화
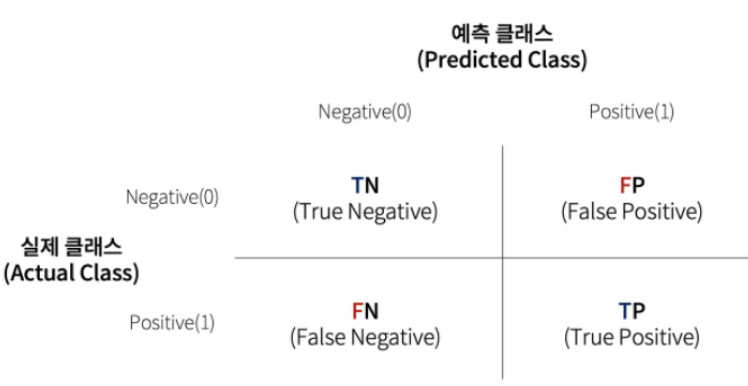
<오차행렬(혼동행렬)>
- 어떠한 유형의 오류가 발생하고 있는지를 나타내는 값.
- 이를 시각화한 것을 오차행렬도 또는 혼동행렬도라고 칭함.
- 정확도(score)의 값과 오차행렬도의 시각화 결과로 최종 모델을 선정한다.
<해석 방법>
- 긍정(Positive)적 오류인지, 부정(Negative)적 오류 인지로 해석함
(→ 위험한 오류)
* FP(False Positive)
: 예측 결과가 맞지는 않음(False)
: 긍정적(Positive)로 해석함
: 위험하지 않은 오류
* FN(False Negative)
: 예측 결과가 맞지는 않음 (False)
: 부정적(Negative) 오류로 해석함
: 위험한 오류로 해석
: FN의 값이 크다면, 정확도(score)의 값이 높더라도 예측모델로 사용하는데 고려해야함
* TP(True Positive)
: 예측결과가 맞는 경우(True)
: 1을 1로 잘 예측한 경우
* TN(True Negative)
: 예측결과가 맞는 경우(True)
: 0을 0으로 잘 예측한 경우
<평가에 사용되는 값 : 정확도, 정밀도, 재현율, F1-score>
* 정확도(Accuracy)
- 예측결과가 실제값과 얼마나 정확한가를 나타내는 값
- Accuracy = (TP + TN) / (TP + TN + FP + FN)
* 정밀도(Precision)
- 모델이 1로 예측한 데이터 중에 실제로 1로 잘 예측한 값
- Precision = TP / (TP + FP)
* 재현율(Recall)
- 실제로 1인 데이터를 1로 잘 예측한 값
- Recall = TP / (TP + FN)
- 위험한 오류가 포함되어 있음 (부정적인 오류가 많다는 뜻)
* F1-Score
- 정밀도와 재현율을 조합하여 하나의 통계치로 반환한 값
- 정밀도와 재현율의 평균이라고 생각해도 됨
- F1-Score = (정밀도 * 재현율) / (정밀도 + 재현율)
<최종 모델 선정 방법>
- 과소 및 과대 적합이 일어나지 않아야 함
- 재현율과 F1-Score가 모두 높으면 우수한 모델로 평가할 수 있음
- 재현율이 현저히 낮은 경우에는 모델 선정에서 고려, 또는 제외⭐
시각화 - 오차행렬도
- 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
"""한글처리"""
plt.rc("font", family = "Malgun Gothic")
"""마이너스 기호 처리"""
plt.rcParams["axes.unicode_minus"] = True
import numpy as np
"""오차행렬 계산 라이브러리"""
from sklearn.metrics import confusion_matrix
"""오차행렬도 시각화 라이브러리"""
from sklearn.metrics import ConfusionMatrixDisplay
- 오차행렬의 기준 특성은 종속변수 기준 : 훈련에서 사용한 종속변수의 범주 확인하기
rf.classes_
출력 : array([0., 1.])
- 오차행렬 평가 매트릭스 추출하기
cm = confusion_matrix(test_target, y_pred, labels=rf.classes_)
cm
출력 : array([[266, 75],
[ 69, 890]], dtype=int64)
※ len(test_target) = 1300 → (4등분) → [266, 75],[ 69, 890]
- 오차행렬도 시각화 하기
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=rf.classes_)
disp.plot()
### 내부적인 오류가 없는지 확인하는 것
### 오차행렬의 긍정 부정 이미지 확인하기
출력 :

분류모델 평가하기
- 라이브러리
"""정확도 : 훈련 및 검증 정확도에서 사용한 score()함수와 동일함"""
from sklearn.metrics import accuracy_score
"""정밀도"""
from sklearn.metrics import precision_score
"""재현율"""
from sklearn.metrics import recall_score
"""f1-score"""
from sklearn.metrics import f1_score
- 정확도
acc = accuracy_score(test_target, y_pred)
acc
출력 : 0.8892307692307693
- 정밀도
pre = precision_score(test_target, y_pred)
pre
출력 : 0.9222797927461139
- 재현율
rec = recall_score(test_target, y_pred)
rec
출력 : 0.9280500521376434
- f1-score
f1 = f1_score(test_target, y_pred)
f1
출력 : 0.9251559251559252
⭐ 해석⭐
- 정확도는 0.89로 높은 편이며,
- 정밀도, 재현율, f1-score의 값이 0.92 이상으로 매우 높은 값을 나타내고 있음
- 따라서, 랜덤포레스트 모델을 이용해서 해당 데이터에 대한 예측을 하는데 사용가능
- 즉, 예측모델로 사용가능
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝ML]모델 파일 저장 및 불러오기 (1) | 2023.12.29 |
|---|---|
| [머신러닝ML] 머신러닝 실습 - 다중회귀모델(Multiple Regression) (1) | 2023.12.21 |
| [머신러닝ML] 머신러닝 실습 - 선형회귀모델(LR; Linear Regression Model), 다항회귀모델(곡선) (0) | 2023.12.21 |
| [머신러닝ML] 머신러닝 실습 - KNN모델(회귀모델) (0) | 2023.12.21 |
| [머신러닝ML]머신러닝 실습 - 생선 구분하기(K최근접이웃 모델, KNN) (2) | 2023.12.20 |




